


Book Review: Overdiagnosed
A fool and his money are soon parted -- or a boob and her boobs, as the case may be

There are deals most people probably wouldn’t take if they understood the outcome spreads. Playing the lottery is one (unless maybe you’re a crack statistician). Scanning all digital communications for evidence of rare crimes is another. Submitting to certain common medical screenings is another.
These are all deals where the common overwhelms the rare. In a delicious irony, missing the fact that the common overwhelms the rare — the base rate fallacy — is itself a common cognitive bias linking massive preventable harms across many domains. But, usually, we see case studies demonstrating empirically that this is a problem in one context — and not the broader extension.

Call it the base rate fallacy fallacy — the misconception that the featured case is a unicorn, when really there are lots of cases like it. Some share an identical mathematical structure (e.g., mass screenings for low-prevalence problems, MaSLoPP). Others are similar in important ways (e.g., mass preventive interventions for low-prevalence problems). Society needs to regulate these structures, because otherwise they wreak predictable havoc. I have some idea how to do that in the security realm, and also how such efforts are doomed to fail. I’ll discuss those ideas in a future post.
This post is about the vast universe of mass screenings for asymptomatic medical problems partly surveyed in Overdiagnosed: Making People Sick in The Pursuit of Health by H. Gilbert Welch, Lisa M. Schwartz, and Steven Woloshin (MDs; Beacon Press, 2011). Over-diagnosed is America-centric, a bit dated, and splendid — an overall fun, well-organized, and informative read. In fact, it’s the best book I’ve read about the implications of Bayes’ rule — the mathematical theorem that says subgroups matter — that doesn’t mention it. But I guess that’s what most people want in a book about any given mathematical theorem?
Here’s a haiku summary, something I used to make for books in grad school, because otherwise my summaries tend to have a certain distinctly un-summary-like quality:
Medicine is an
industry; buyer beware —
hold onto your boobs!*
*Men, please substitute balls. Have a quick look at the risks and benefits of early detection of breast cancer by mammography screening and early detection of prostate cancer with PSA testing if you don’t know what I’m talking about.
Main Point, Main Pattern
Welch et al’s main point is that, previously, medicine used to diagnose and treat only the most severe cases of a wide range of problems. But technological advances let us diagnose earlier and treat milder cases more easily than ever before. This sounds great.
It’s not. The milder the case, the less likely that treatment prevents a big problem, and the more likely it causes a problem, instead. But, in many cases, it’s hard to know for sure who was overdiagnosed, e.g., with an early detected cancer that was going to resolve on its own anyway.
Use of bad metrics is rampant — metrics that don’t tell us what we need to know, like whether early diagnosis and treatment promotes or degrades quality of life, and whether it net prolongs or saves lives. Five-year survival is my favorite such bad metric, because Welch et al have great illustrations and explanations of how lead-time bias (Figure 10.1, p. 145) and overdiagnosis bias (Figure 10.2, p. 146) can increase it without lengthening or saving any lives.
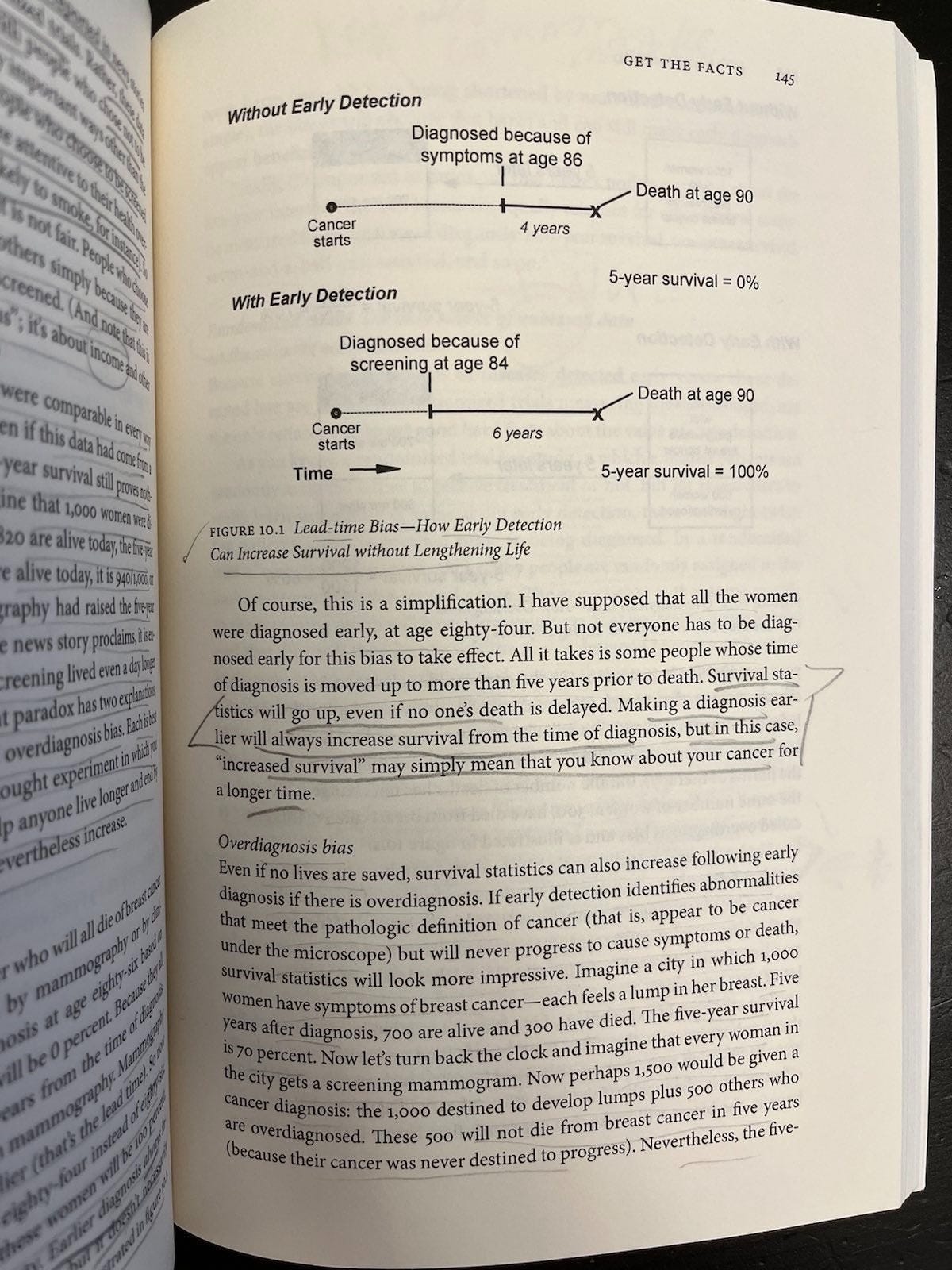
This may sound like a medical version of the same story I keep telling: New tech promises to advance vital public interests, but hits old limits from universal mathematical laws that often make MaSLoPP backfire, endangering the very people it’s trying to protect. It is. (It’s not my story; it’s the ancient Greek story of hubris and nemesis with a bunch of statisticians’ work layered on top over time.)
But medical MaSLoPP may warrant a different regulatory approach than security MaSLoPP. One reason is that we make collective decisions about mitigating risks in security, but individual ones about health. Reasonable people could opt into or out of many medical MaSLoPP on the basis of their own histories, risk factors, feelings, and preferences about what constitutes a good life — and a good death. And it would be wrong for clinicians to withhold information to let patients make those decisions. At the same time, clinicians are possibly not the best people to be in charge of that risk communication. But, you might argue, they’re subject-area experts sworn to first do no harm; so why not?
Structural Incentives
In Welch et al’s account, there seem to be four main sorts of structural incentives driving medical overdiagnosis: positive feedback loops for patients and clinicians having/ordering more and more screening tests (psychosocial forces), asymmetric legal risks for docs to not order versus to order tests even though both courses of action can do preventable harm (legal forces), political incentives for policymakers to support screenings lacking evidentiary basis in order to look tough on [problem] for popularity points (e.g., profiteering from socially and politically powerful social networks, and winning naive popular support for reelection), and asymmetric financial incentives (all over the place, but especially corporate corruption). The logical basis for the psychosocial component may need further development. These incentives reflect system-level problems that we should not expect individual-level solutions to solve, as Chater and Loewenstein argue. And it’s worth mentioning uncertainty aversion as another factor driving overdiagnosis — and linking it with underdiagnosis.
Positive feedback loops
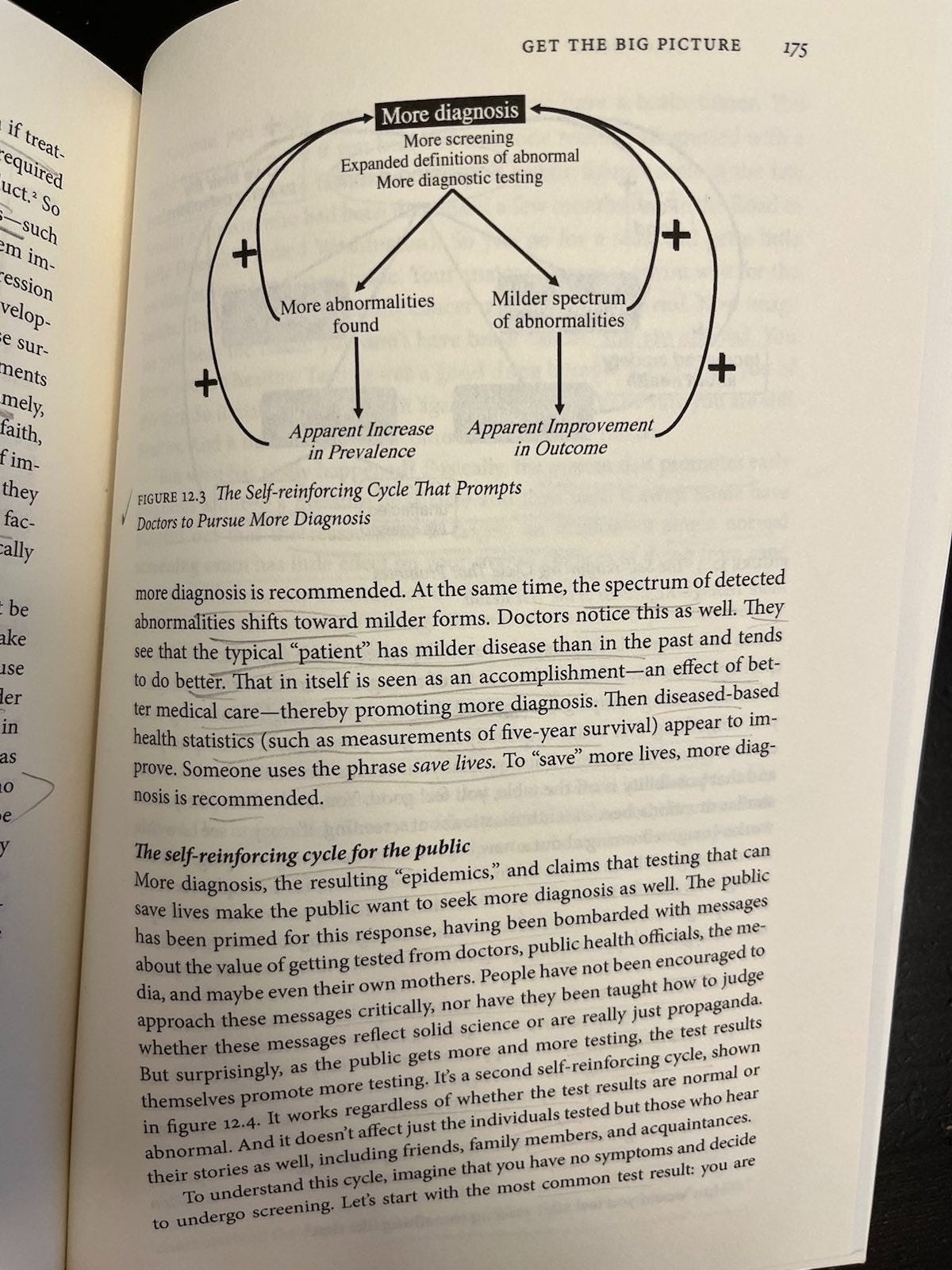
According to Welch et al, more diagnosis triggers positive feedback loops among doctors (p. 174-5) and patients (p. 176-8) like. These loops do not necessarily correspond to improved outcomes. The loops work like this:
For doctors (Figure 12.3): Milder abnormalities tend to have better outcomes anyway, so seeing a diagnosis explosion combined with apparent outcome improvements is like adding water to a solution and saying it’s getting weaker. Yeah, it’s getting weaker because you diluted it. So adding a bunch of mild cases to a collection of severe ones may make incidence appear to rise and outcomes appear to improve, making doctors feel really good about their early diagnosis efforts; but without moving those metrics we really care about (e.g., related deaths).
For patients (Figure 12.4): Screening only seems ever to promote more screening, regardless of test result. Normal results create relief, false alarms ultimately do too, consequential disease either can’t be helped (then you die) or can (then you credit the test for saving your life), and overdiagnosis (you were diagnosed and treated unnecessarily) is often plagued by persistent epistemic uncertainty that people can misinterpret as certainty (e.g., thinking the test saved your life when it’s not clear and/or probably didn’t).
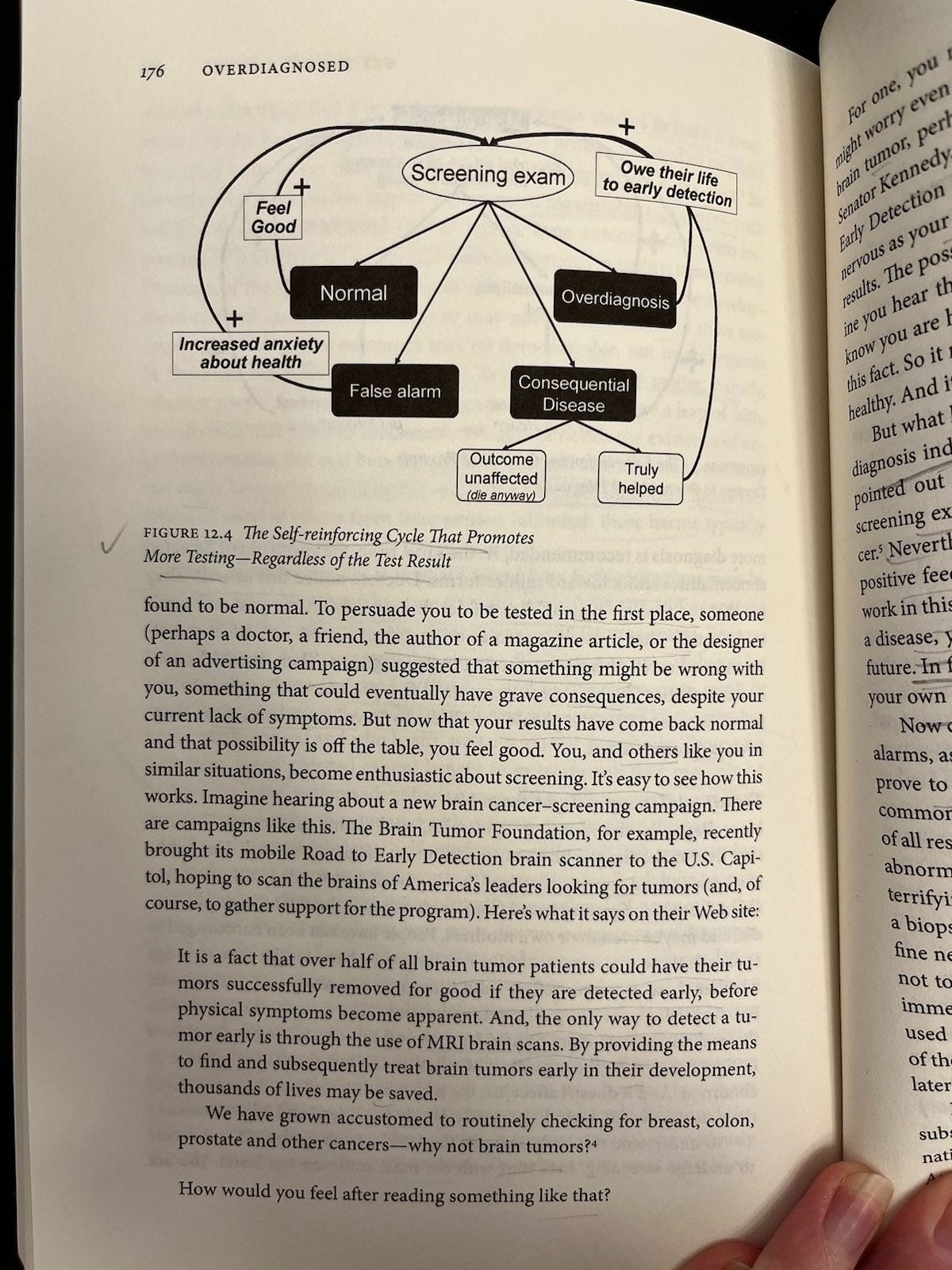
I am not sure about these loops. Granted, they are heuristics, and there is something to them. But they are wrong, and maybe not just in the way all heuristics are wrong.
They are wrong, because screening has negative effects, too. Welch et al are not the only people to notice these negative effects. Simply not drawing them into pictures of feedback loops doesn’t make them not exist. Defining the feedback loops as exclusively positive doesn’t make sense if there are also negative feedbacks in these pictures, and we care about net effects.
This raises an important if slightly tangential point: There are so many critics of controversial mass medical screening programs like mammography for breast cancer and PSA for prostate cancer. Many of them are so brilliantly articulate in their criticisms, and part of such interesting sub-stories in their own rights, that I have been putting off writing about these case studies for a while. It would take at least one dissertation to comprehensively survey and credit all the smart people who have done outstanding work on any one of these cases, and more to tell all the interesting stories of which that work is an integral part.
Some of my favorites, like Bewley and Marmot, seemed at first glance to be missing from Overdiagnosis; but it turns out they’re “missing” because they came out after the book was published. This highlights another important if slightly tangential point: Controversies over these programs and others like them have been repeating for a long time. The citations and political scenery change, but the structural incentives stay the same. So this seems like another area where a sensible society would regulate the class instead of repeatedly fighting programs that share the same structure.
Yet, like another remake of a familiar classic, the mammogram recommendation saga is repeating again in the U.S. this season: This past May, the U.S. Preventive Services Task Force changed its mammogram recommendation to advise women to start screening at 40. This is part of a long series of back-and-forth recommendation changes; before, the U.S. recommendation was to start at age 50. Before that, the first nationwide U.S. mammography program launched in 1973 including women 35+, and the American Cancer Society excluded women <50 in 1976 due to radiation exposure concern (p. 74). There was another back-and-forth in 1988 (pro younger screening), 1993 (NCI/con, citing Suzanne W. Fletcher’s excellent “Whither Scientific Deliberation in Health Policy Recommendations? — Alice in the Wonderland of Breast-Cancer Screening,” NEJM 336 (1997): 1180-83), 1997 (con and reversed under political pressure to pro younger screening), 2009 (con younger screening; p. 74-76), and again this fall. Critics like Gøtzsche have long argued “Mammography screening is harmful and should be abandoned” on the basis of no proven net mortality benefit in exchange for substantial iatrogenic harms from secondary screening and treatment. So what other incentives are stacking the deck?
Asymmetric legal risks
On one hand, instead of just positively reinforcing ever more testing as Welch et al propose, psychosocial forces seem like they should cut both ways sometimes on the basis of widely noted negative feedback (e.g., false positives associated with unnecessary, risky, and disfiguring procedures); so these dynamics may not be as asymmetric as the authors make them out to be. On the other hand, the case for asymmetric legal risks seems sound. At least, it describes a legal reality that is a social reality with supporting anecdotes. That reality is that underdiagnosis is “subject to legal penalty while overdiagnosis is not” (p. 163). And, in deciding whether penalties apply in cases of alleged underdiagnosis, the scientific reality does not determine the social one. Are legal risks to practicing clinicians really so asymmetric and discordant with empirical, statistical and human realities?
In a variety of searches for disconfirming information, I didn’t find any hits reflecting medical liability for overdiagnosis — only indeed underdiagnosis. For instance, I Googled “can you sue a doctor for recommending mammography without accurately describing risks and benefits”; the first hit is Leonard Berlin’s 2002 AJR article “Malpractice Issues in Radiology: Liability for Failure to Order Screening Examinations.” A number of PubMed searches on similar terms (e.g., cancer screening liability; mammography cancer screening liability) turned up similar results. It seems people are free to choose what many would call a bad deal, clinicians are not free to not offer it to them (they’re liable for underdiagnosis), and if patients have risk literacy problems, that’s their problem.
Consider the case of mammography for early breast cancer detection. If I have a complaint with Overdiagnosis as a great fan of its many lovely tables and figures, it’s that they’re not already open-source as far as I can tell. Luckily, the Harding Center for Risk Literacy also famously summarizes mammography’s benefits and risks according to the best available evidence here:
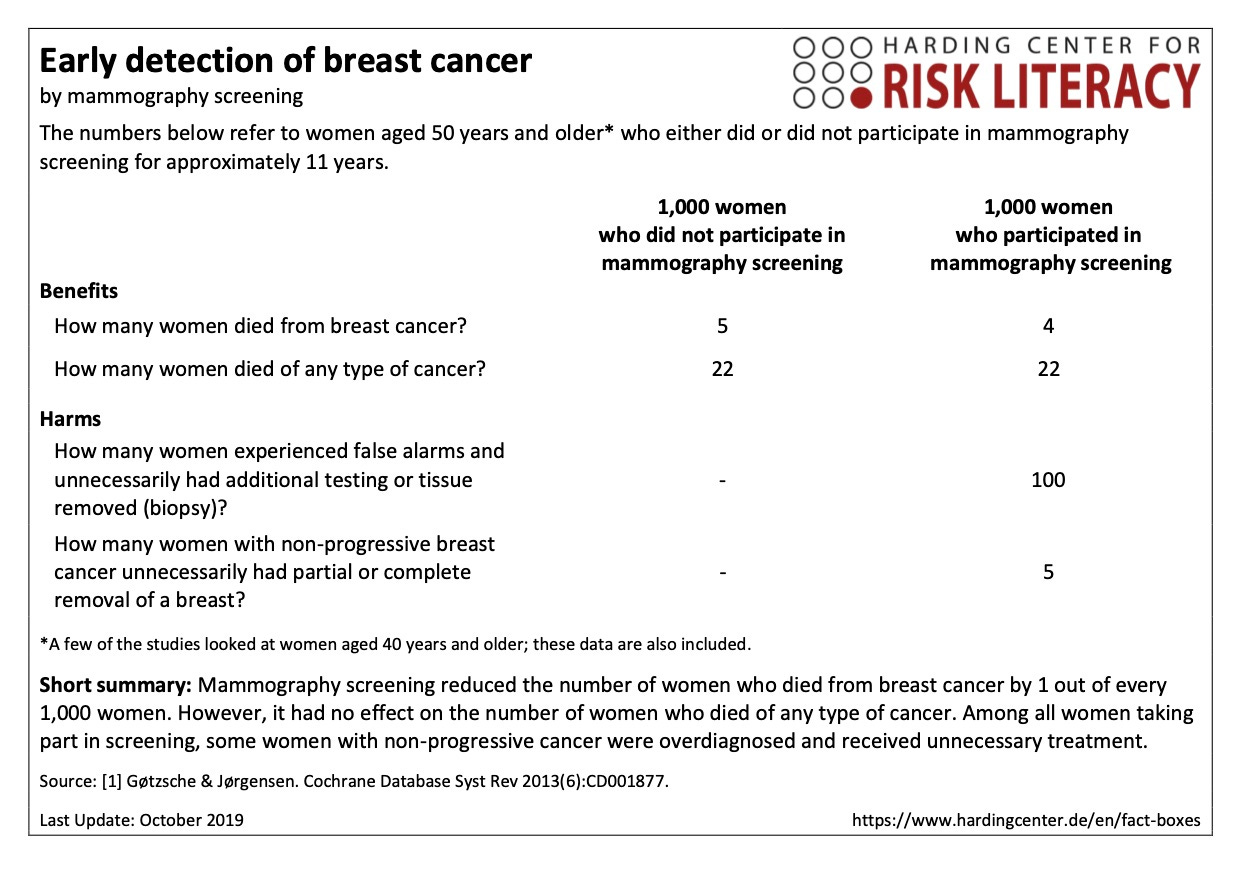
The benefit: In 1,000 women who participated in mammography screening for around 11 years, researchers estimate that one breast cancer death was prevented. (Gøtzsche estimated it at one in 2,000 over 10 years.) It’s not clear that this translates to an all-cause mortality benefit. In other words, mammography has not been demonstrated to save lives. It’s fair game to hone in on that one saved life from breast cancer; it’s also fair game to wait for the all-cause mortality jury to come back, although then you’ll probably be waiting for a long time. Mammography may be one of the best-studied medical interventions ever (10 randomized trials at Welch et al’s writing), and we still don’t have enough data to know if it net saves lives — just that it net saves about one life in 1,000 from breast cancer death.
The risk: In turn, 100 of 1,000 mammography screened women had false alarms, often leading to biopsies — and 5 with non-progressive breast cancer unnecessarily had partial or complete removal of a breast. That usually means DCIS (Ductal Carcinoma in Situ); more on this later. These biopsies may contribute to the spread of cancer cells (we don’t know). These mastectomies are major surgery, with all its risks (including death). There are concerns that radiation exposure from repeated mammography screening may contribute to cancer incidence and deaths. Similarly, there are also concerns that mammography compression may contribute to the spread of some cancers (we don’t know).
A brief meta-science note on the multiple discourses involved here, and their usual mistakes: The cited article in the last instance — Förnvik et al’s “Detection of circulating tumor cells and circulating tumor DNA before and after mammographic breast compression in a cohort of breast cancer patients scheduled for neoadjuvant treatment” in Breast Cancer Research and Treatment, 177, p. 447–455 (2019) — makes classic statistical significance misuse interpretation mistakes, but the evidence it reports suggests that compression-related spread could be a problem: We don’t know. Some case reports are concerning. Nonetheless, there are a lot of “misinformation” debunking search results stating in no uncertain terms that mammography compression does not contribute to cancer spread, when the reality is that we don’t know. This appears to be another instance of uncertainty aversion contributing to misinformation in misinformation discourse itself, as is also common, e.g., in the Covid and abortion discourses (no surprise, since calling something “misinformation” in the first place is a political act). This reflects a pervasive pattern of ambiguous evidence, dichotomaniacal scientific misinterpretation, and parrot-like misinformation discourse misrepresentation of uncertainty as certainty. The pattern reoccurs in the case of needle biopsy risk spread, as in many other contexts. Experts often tell subjects to trust them, not worry, and undergo the procedures that they implement. But they have structural incentives to do this.
Returning to the issue of asymmetric legal risks, how weird is it that doctors can encourage people to subject themselves to overwhelmingly unnecessary and often harmful interventions including life-threatening, body-mutilating surgeries, and there’s no legal penalty for that — but there is legal liability for not recommending this mass screening for the low-prevalence problem (around 1/1000) of a breast cancer that would cause death if not caught early by mammography and treated, but may not help anyone live longer or better in the end? Especially considering that doctors don’t profit from recommending against medical screenings, but some doctors and healthcare systems do profit from recommending some of them - stacking the structural incentives further in favor of overdiagnosis. The legal system is supposed to theoretically help counterbalance perverse incentives like that, but here it seems to be making the situation worse. As if the legal system is one part of the larger psychosocial structure that supports rather than counterbalancing power dynamics in the status quo.
Asymmetric financial incentives
Welch et al mention three categories of asymmetric financial incentives that might be in play here, albeit without listing them together as far as I can see, or thinking about how to articulate a typology of these incentives in structural terms that might travel across contexts outside medicine. If I have an organizational complaint about Overdiagnosis, it is that more of this meta-level articulation might have helped me feel less swimmy as I try to structure my own meta-level thoughts. But who knows if that is the authors’ problem, mine, or a little bit of both. It is possible, though, that my typology is bad or wrong, and improvements are welcome.
These three articulated categories of asymmetric financial incentives driving overdiagnosis are: (1) direct, individual medical provider (office)-level financial incentives to produce more patient medical information using existing equipment (aka conflict of interest; see also Monty Python’s “The Machine That Goes Ping”); (2) the same thing but on the larger level of units like hospitals or academic medical centers; and (3) the larger sociopolitical web of power in which making people sick in both senses (defining them as patients, and making them ill) is profitable, and the currents of social reality pull firmly in the direction of these profits.
Here is a bit more about each of these types of asymmetric financial incentives driving overdiagnosis. As a matter of typology, I propose thinking about them as local, regional, and national; or peripheral, central, and systemic; or some similar categorization that references the way in which the people getting the goodies in these respective categories are small fish, bigger fish, and the biggest fish in the grand scheme of sociopolitical power. Maybe just calling them small, bigger, and biggest fish actors works, since in the case of the medical-industrial complex, the system includes some actors from the small and bigger categories — just like a big fish that contains small and bigger fish below it in the food chain.
(1) Small fish.
Some doctors do stand to profit greatly from more diagnosis. Doctors who have financial incentives to pursue more diagnosis include those who primarily do diagnostic procedures (such as gastroenterologists who do endoscopies and cardiologists who do heart catheterizations) and those who own testing equipment (such as radiologists who own imaging centers and primary care physicians who own the equipment to perform lab tests, stress tests, echocardiograms, and bone-density tests). For many doctors, however, the financial incentive is minute, if it exists at all (p. 160).
Small fish financial incentives for overdiagnosis appear to be linked by doctors owning what economists would call the means of production (here, production of patient medical information). No surprise that doctors produce too much information, in effect, if their payment depends on producing it. The same incentives also drive bigger fish, like academic medical centers — but they’re playing for bigger stakes as well…
(2) Bigger fish.
I could be wrong, but I think maybe Welch et al mix up levels 2 and 3 a bit, and the next level up logically is actors like hospital systems playing the same game as doctors who profit from producing medical information on patients using equipment that they own. They say:
The larger truth is that creating new patients and making more diagnoses benefits an entire medical-industrial complex that includes Pharma but also manufacturers of medical devices and diagnostic technologies, freestanding diagnostic centers, surgical centers, hospitals, and even academic medical centers.
Take screening, for instance. Screening can be a great loss leader for hospitals. A loss leader is an item a seller intentionally prices well below cost in an effort to stimulate other, profitable sales later. Supermarkets do this all the time. Increasingly, hospitals are trying it (p. 156)
In terms of their profits, the number of people their work impacts, and their political power, hospitals are smaller fish than drug companies. But maybe Welch at al are just arguing here that Big Pharma gets enough flak as it is, and we need to also extend our critiques of medical profiteering to the very hospital systems that appear to save us. That rings true. It also rings true that there’s a larger systemic level we need to have on the board; but that seems to be a separate issue. In terms of organizing a typology of financial incentives going up the food chain, a hospital system profiting from underpricing screenings to make more money off patients and their families later looks like a bigger-fish version of a doctor imaging patients more to make more money.
It’s worth noting Welch et al cite former NEJM editor Arnold Relman here, who coined the term “medical-industrial complex” and critiqued medicine’s market makeover in A Second Opinion (2007). You can’t say this without citing Altman’s classic “The scandal of poor medical research”; but they do, again highlighting the book’s focus on practice to the exclusion of other areas of medicine. Anyway, I slot this sort of critique under the biggest level of asymmetric financial incentives driving overdiagnosis…
(3) Biggest fish.
This level of financial incentive is about the largest-scale dynamics of systemic sociopolitical predation as they manifests in medicine among other realms. It includes corporate incentives that can affect diverse actors, from researchers and clinicians to patient support group volunteers and policymakers. Corporate conflicts of interest (COI) are conspicuous, for instance, in the context of the thresholding changes (more on this later) that redefined millions of Americans as sick:
The head of the diabetes cutoff panel was a paid consultant to Aventis Pharmaceuticals, Bristol-Myers Squibb, Eli Lilly, GlaxoSmithKline, Novartis, Merck, and Pfizer — all of which make diabetes drugs. Nine of the eleven authors of recent high blood pressure guidelines had some kind of financial ties… to drug companies that made high blood pressure drugs. Similarly, eight of the nine experts who lowered the cholesterol cutoff were paid consultants to drug companies making cholesterol drugs. And the first cutoff for osteoporosis was established by a World Health Organization in partnership with the International Osteoporosis Foundation — an organization whose corporate advisory board consisted of thirty-one drug and medical equipment companies (p. 24)
Overdiagnosed focuses on medical practice. This is both a strength — there’s a lot of ground to cover here, and the book excels at exploring and linking similarly structured problems across diverse issue areas in medical practice — and a weakness — it leaves a lot out, particularly when it comes to how medical education and social policies fit into the bigger picture. For instance, Maryanne Demasi reports that corporate funding pervades U.S. medical research, education, and health policy, contributing to high sugary drink and processed food consumption among lower-income households; by contrast, Denmark incentivizes whole food buying through its low-income food card program. (Chater and Loewenstein call this type of solution s-frame for system as opposed to i-frame for individual, citing Afshin et al. 2017 as an example of subsidies for healthy food combatting obesity.)
But Welch et al do acknowledge that related and similar incentives also influence other healthcare experts across the related realms of medical research and health policy — and beyond, in the popular health discourse that shapes market forces that drive demand for mass screenings:
“Most medical research is now funded by industry (p. 159 citing Moses, Dorsey, Matheson et al, “Financial Anatomy of Biomedical Research,” JAMA 2005; the fact is still current). Industry strongly determines what research questions get pursued (which explains why there are far more studies on drugs to treat osteoporosis than on how to prevent the elderly from falling). And doctors can also be swayed by government reports, which are arguably the least biased sources of information.
And then there’s the media. News and infotainment (such as talk shows) are always looking for engaging, simple stories. Stories about new diagnostic technologies or the value of early diagnosis fit the bill perfectly. Providers, researchers, and disease advocacy groups know this and are happy to supply the material. Unfortunately, these stories usually include a powerful but misleading anecdote - preferably a testimonial from a celebrity or a politician — and fail to include any discussion of the nuances involved in early detection. That, in a nutshell, is the system that promotes more diagnosis. (p. 160).
I should point out that Welch et al take great pains to frame their criticisms of perverse incentives in relation to the point that there can also be elements of “true belief” among doctors, patients, and everyone else. But that I don’t see that belief as being necessarily separate from the way in which financial incentives are stacked. Rather, money is power, and power can influence both belief and behavior. “It’s hard to get a man to understand something his job depends on him not understanding,” as the saying goes.
Welch et al also mention bad political behavior around overdiagnosis that I slot in the biggest fish category because it sometimes involves national-level policymakers (e.g., Congress). In brief, we see evidence that perverse incentives also shape health policy when policymakers interfere in scientific assessments of medical interventions for political gain. For instance, this happened with one of the mammography pendulum swings in 1997, when a National Cancer Institute panel reviewed the available evidence and suggested it wasn’t strong enough to recommend mammography for women in their 40s (p. 75-76). It wasn’t and isn’t, but this was a very politically unpopular conclusion that the Senate itself opposed, voting “for a nonbinding resolution supporting mammography for women in their forties. No one wanted to be on the wrong side of this issue — the vote was 98 to 0” (p. 76). Under political pressure, the National Cancer Institute reversed its own panel’s recommendation, recommending mammography to women from age 40.
There may be a corporate profiteering aspect to this, there may only be a political expediency aspect (which is still financial insofar as politicians can make money by serving in office, and this is about looking good for reelection), or both. This structural problem resonates with the same problem in other contexts, including proposed mass security screenings like Chat Control. Politicians can advance their interests promoting policies that appear to advance values like health and security, even if those policies may demonstrably backfire. The empirical world’s power to rationally move complex human societies’ structural levers in societal interests is limited by bias, error, and perverse incentives. The relevant biases and errors are too numerous to list, but uncertainty aversion seems to link many common cognitive distortions.
Uncertainty aversion links overdiagnosis and underdiagnosis
So let’s say we have pervasive corporate COI, political expediency, and dynamics of systemic sociopolitical predation all playing a part in driving overdiagnosis and preventably harmful overtreatment of disease in currently asymptomatic patients. This is not to be confused with underdiagnosis and undertreatment of currently asymptomatic patients, another substantial problem that Welch et al entirely bracket. It would be interesting to think about how these twin problems relate. My hypothesis is that increasing quantification tracking with increased bureaucratic demands for proof and certainty make it easier for busy clinicians and precarious researchers to run and act on the results of defensible, standardized screening tests than they do for the same groups to listen to complex patient histories and spend time thinking about, discussing, and experimenting to solve the implicated puzzles. So uncertainty aversion would then be the psychosocial link driving suboptimal medical care causing common and preventable harm across many subfields.
Because I was recently asked by a subject-area expert I regard with the utmost respect for evidence behind the claim that underdiagnosis of symptomatic patients is also a problem, here’s some from my Springer chapter on the lupus case study with which I’m familiar:
… the current focus on diagnostic criteria means precisely that ‘Organ damage might accrue in a prodromal period prior to a formal diagnosis of SLE being made,’ although these treatments [the standard low-dose steroids and hydroxychloroquine] can help prevent that damage. At the same time, an online survey of 3,022 self-reported lupus patients found that most (54.1%) reported having been told there was nothing wrong with them or that their symptoms were psychological…
Changing the parameters of diagnosable autoimmune disease follows the best available evidence to prevent harm, and is thus well worth doing. For example, prodromal lupus patients treated with hydroxychloroquine or prednisone had delayed classifiable SLE onset, and hydroxychloroquine was also associated with fewer later autoantibody specificities, according to a retrospective study of 130 military personnel. Indeed, this already appears to be standard practice in some places, with the majority of incomplete or potential lupus patients at Brigham and Women’s Hospital (66% of 161 patients) and in the Spanish Rheumatology Society Lupus Registry (around 69% of 345 patients) treated with antimalarial medication. These observations still suggest a substantial minority of affected patients (within the universe of identified patients) miss out on effective preventive treatment for unspecified reasons, suggesting room for improvement through updated consensus guidelines.
The large number of recent books about women’s difficult experiences in the medical system lead me to believe this is not sui generis. See, e.g., Caroline Criado Perez’s Invisible Women: Exposing Data Bias in a World Designed for Men (2019), Elinor Cleghorn’s Unwell Women: A Journey Through Medicine and Myth in a Man-Made World (2021), Sarah Graham’s Rebel Bodies: A guide to the gender health gap revolution (2023), and Maya Dusenbery’s Doing Harm: The Truth About How Bad Medicine and Lazy Science Leave Women Dismissed, Misdiagnosed, and Sick (2018). It’s not hard evidence, but this list suggests to me that a lot of women have (probably valid) complaints about underdiagnosis — and they’re buying books.
So critiques of overdiagnosis should take care, as Welch et al do, to distinguish their critiques as dealing with asymptomatic, not symptomatic, patients. At the same time, we may also want to think about how zero-sum resources used for largely ineffective or harmful mass screenings for low-prevalence problems are then unavailable to address symptomatic problems. Some MaSLoPP critics do think and talk about this problem — e.g., in the very different context of Chat Control, where it is feared that resources needed for investigating false positives from mass screening would subtract from already inadequate resources needed for promptly investigating cases that come to law enforcement attention through other channels, like hotline calls with specific information. Might clinician time needed for difficult diagnoses be going to implementing MaSLoPP instead?
Moving from this typology of incentives to a typology of case studies where overdiagnosis is a problem, Welch et al examine threshold changes, imaging advances, and asymptomatic cancer screenings. These are all MaSLoPP.
Threshold Changes
When it comes to hypertension, diabetes, high cholesterol, and osteoporosis, threshold changes have mandated doctors diagnose more patients with milder disease, sooner. This flagged millions of Americans more for (profitable) treatment — treatment that risks doing harm and, in most cases, yields no benefit. Which cases are those?
We don’t know. “A few may be helped, a lot will be overdiagnosed, and some of them will be harmed. And no one knows who is in which group” (p. 25). This kind of persistent epistemic uncertainty should set your dichotomania censors tingling. Because uncertainty can code as threat, we might expect discourse around these sorts of screenings to struggle with denying or reclassifying away what are often irreducible uncertainties. It’s also worth noting that this few helped/many overdiagnosed (and some of them harmed) outcomes spread should be familiar from MaSLoPP.
More recent threshold changes have added several additional disorders to Welch et al’s list. For example, gestational diabetes also fits the pattern of threshold change and resulting diagnosis explosion — with critics charging net iatrogenic harm (popular; scientific). Proponents say screening lowers stillbirth risk.
They can both be right due to the inescapable accuracy-error trade-off. More screening and a lower diagnostic threshold means more gestational diabetes diagnosis and treatment, most of which may be overdiagnosis, much of which may do preventable harm, and some of which may (rarely) prevent stillbirth. But maybe those risks could instead be reduced through ModiMed-type diet and lifestyle intervention that might help a broad range of people achieve better metabolic, cardiovascular, and mental health — regardless of whether they are pregnant, regardless of where they fall on blood sugar test distributions. Probably making and policing ever finer-grained categories of subjects to be pathologized and surveilled in one way or another is more profitable than helping people impoverished by generations of late capitalist exploitation relearn basic life skills like cooking and eating more fruits and vegetables. It certainly looks more sciencey and is clearer how to bill for the lab work, diagnosis, and treatment track. But that doesn’t actually make it more evidence-based or effective.
So why are threshold changes like this examples of MaSLoPP? Because the outcomes we really care about, like preventable deaths from heart disease or gestational diabetes, are rare, while the screenings for increasingly generous ranges of “abnormalities” are mass in the sense that doctors routinely conduct these screenings on entire populations (e.g., all pregnant women). Similarly, imaging advances have introduced a range of new medical MaSLoPPs…
Imaging Advances
Do not adjust your sets or check your glasses for X-ray vision swirls. Technological advances have made visible what was once invisible: internal organs, vascularities, genomes, and unborn babies. This raises the specter of MaSLoPP in these contexts, since problems we both care about and can do something about are quite rare in relation to how often their possibilities can be identified through imaging.
Seeing Your Incidental Insides
Sometimes, doctors don’t even know what they’re looking for until they find it: “incidentalomas” — minor tumors or growths discovered by surprise on imaging for unrelated purposes (p. 91) as “a side effect of doing more scanning at such high resolutions” (p. 100). Finding more cancer? Sounds great.
It’s not. Welch et al have a beautiful table (Table 7.1, p. 95) showing that it’s overwhelmingly likely these findings are not lethal cancers: 96.4% for incidentalomas of the lung in smokers, 99.3% for incidentalomas of the lung in never-smokers, and 99.8%, 99.5%, and >99.99% for kidney, liver, and thyroid incidentalomas, respectively. This table should come standard with imaging reports describing these abnormalities.
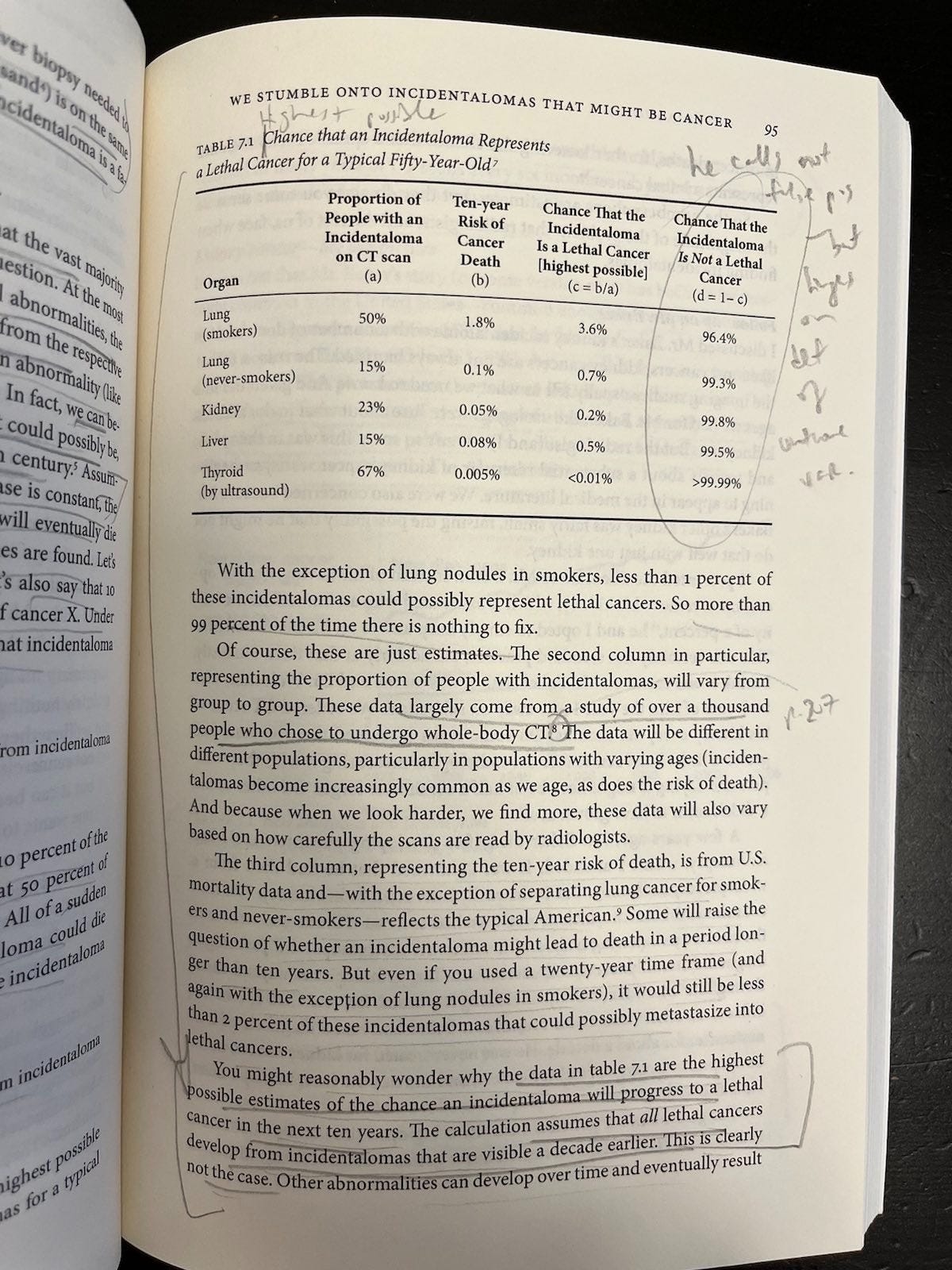
It doesn’t, and these incidentalomas cause a lot of patients a lot of anxiety, and often a lot of follow-up hassle (and expense) in monitoring them over time. Most doctors, say Welch et al, “view them as a nuisance. Many understand that they have become a real problem” (p. 100).
So Welch et al suggest radiologists should redefine normal (p. 98). “Medical experts set the bar for what’s considered high in blood pressure, cholesterol, and blood sugar; radiologists should decide what’s important in abnormalities rather than just reporting any and all of them” (p. 98).
This is a terrible idea. It throws away information to force the choice the authors want doctors and patients to make — to refrain from doing a bunch of unnecessary and stressful follow-up testing on growths that are not going to kill anyone the vast majority of the time. It strikes me as a possible facet of the book’s dated perspective that the authors basically blurt out “Just lie to people to solve the problem” (my paraphrase) without pausing to identify or reflect on their paternalistic bias. It would be interesting to see an update in which they grapple with the bias, error, and fluidity in science itself that problematize science communication that prioritizes this kind of mitigation over robust, honest risk literacy work that lets people make their own choices based on what we know.
At the same time, maybe there’s something to the ignorance solution they propose to the “too much information” problem in medical imaging or diagnostics more broadly — as long as it’s deliberate ignorance. Incidentalomas overwhelmingly don’t kill people, so maybe people would overwhelmingly choose to not become informed about them if they knew the correct odds at the right time — which probably means setting the preference before the growth is found. Just like we often check boxes and sign to consent to data management in the context of electronic medical records, maybe we should have the option to consent to information management in the context of deliberate ignorance of incidentalomas.
Incidentalomas are just the tip of the incidental insides iceberg. Scanning asymptomatic volunteers, researchers found about 10% have gallstones on ultrasound, 40% have meniscal (knee ligament) damage on MRI, and over 50% have bulging lumbar discs on MRI (p. 36). So odds are, you have experienced your own version of this phenomenon. Here’s mine: I had a spinal compression fracture discovered incidentally on X-ray when I was much younger; it never bothered me, and I probably know where it came from. (I used to carry all my school books, all the time, and be an even smaller, lighter version of the petite woman I became; it felt like it was breaking my back, and it probably was.) But spinal compression fracture sounds bad, so I worried I was weird. Turns out I was normal: “the majority,” Welch et al explain, “are silent and don’t hurt at all (p. 152).
This lesson in how normal it is to be abnormal reminds me of the story of Norma, the average woman who doesn’t exist. The moral of the story is that, as Sarah Chaney wrote for Psyche, “No one is average in everything, and average is not necessarily the same as healthy anyway.” In other words, it’s normal to be different — and putting averages on a pedestal can do harm. We might tailor this moral to the context of mass medical screenings to go something like: No one is normal in everything, and following up abnormal findings with secondary screenings may neither resolve persistent inferential uncertainty, nor improve how well or long you live. In other words, it’s normal to be different — and medicalizing it can do harm.
Seeing Your Vascularities
When it comes to numerous other over-diagnosis case studies, like vascular screening for abdominal aortic aneurysm (the best of the vascular screening tests), Welch et al acknowledge “There’s no right answer. AAA screening will help a few, but will lead many more to worry needlessly” (p. 115). The same is true of most MaSLoPP. But the numbers here, as often, are sobering: A life or two in 1,000 saved by screening, versus 6 unnecessary major operations and 55 in 1,000 requiring “an indefinite cycle of follow-up testing triggered by screening” (p. 114). Welch et al report:
One of my vascular surgery colleagues, Brian Nolan, interviewed thirty-four men undergoing surveillance at our center and found that many do worry: 7 percent of men reported difficulty falling asleep, 25 percent felt overwhelmed, and 48 percent reported unwanted thoughts about the aneurysm… “ ‘I don’t let my grandchildren sit on my lap’; ‘I feel like I am carrying a bomb that could explode at any time’ ” (p. 115).
This metaphor recurs.
Seeing Your Genome
Incidentalomas are not the only case where Welch et al propose a low information environment as the best solution for a risk communication problem. They also say “that would be the best scenario” for mitigating the threat of overdiagnosis in genetic testing: “Perhaps we could ignore all the little changes in risk and communicate only the few really big ones” (p. 135).
Again, this paternalistic approach places a lot of faith in current interpretations of science to be good enough to ignore information when we probably don’t know what it means, and mistakes are common. To be clear, I’m not saying that ordinary people can make great sense of their genomic data. But there are ample reasons to mistrust that experts can make good sense of it, too.
So, if I really cared about assessing genomic information from a medical risk management standpoint, I would want to make sense of the data myself as much as possible. Not trust someone else to pare it down for me before I even got a chance to see it.
But I don’t, because — as Welch et al point out — “The central problem with genetic information is uncertainty — uncertainty about who will in fact get the disease and what should be done about it now. Much of this uncertainty will always be with us, no matter how well we understand biology” (p. 119).
The deliberate ignorance argument may draw strength from this persistent epistemic uncertainty element in many mass screenings.
Seeing Your Unborn Baby
Welch et al also highlight harm from routine obstetric screenings, with ultrasonography for fetal defects in pregnancy (e.g., trisomy syndromes) and continuous fetal heart rate monitoring (CTG) in labor being the best-known examples. It is hard to pick a favorite figure in a book full of great tables and figures, but Figure 8.1 - Effect of Intrauterine Electronic Fetal Monitoring is fun. The figure shows the benefit to harm ratio of labor CTG in terms of fewer seizures versus more C-sections. But the space above “Benefit” is blank, because the event is so rare — whereas CTG escalates “the frequency of C-sections from about 200 in every 1,000 births to 330 in every 1,000 births” (p. 106). It doesn’t appear to be known from available data whether labor CTG lowers or raises newborn deaths, or has no effect; the known trade-off according to a 2017 Cochrane review still appears to be fewer neonatal seizures versus more C-sections.
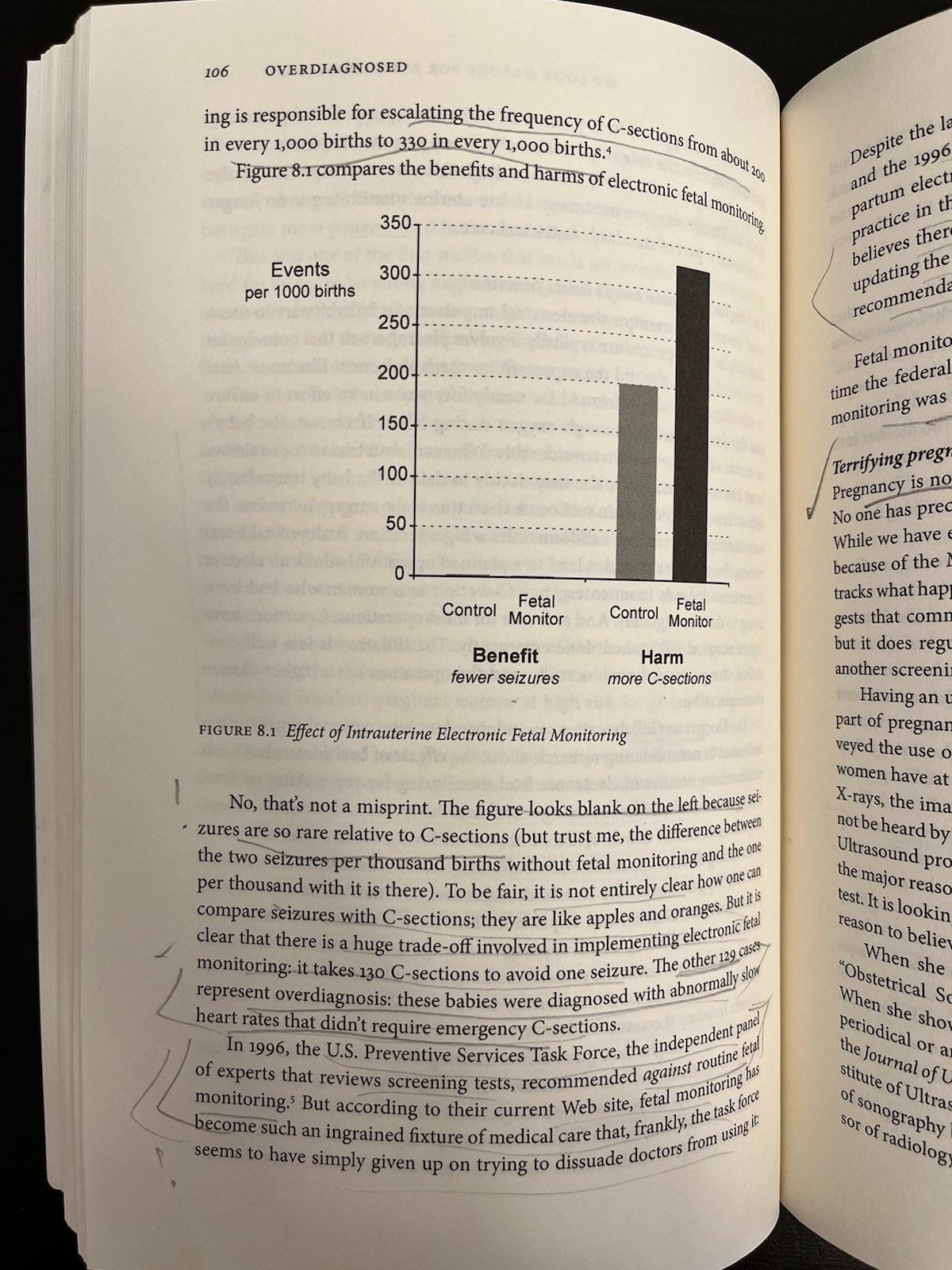
It’s worth noting that it may be increasingly difficult to avoid these screenings despite their recognized overuse. As legal precedents accumulate for death/disability from not detecting problems, hospital systems have increasing, asymmetric incentives to monitor. Psychosocial pressures can also make it difficult for pregnant women and other patients to avoid MaSLoPP even if they know the associated costs and benefits — which most won’t, particularly not on all the possible screenings they’re offered, particularly as part of a heavily surveilled group like pregnant women. Because it’s weird to decline things like ultrasound and CTG in risk-attuned medical and popular cultures that tend to conceive of harm purely in terms of things intervention can mitigate and not also of things it can create. And because pregnant women are culturally encouraged to do everything they can to protect their young — again not necessarily from iatrogenesis, but from everything else. Scholars like Ellie Lee at the University of Kent’s Centre for Parenting Cultural Studies have long critiqued this culture of expert-led constructions of the risk-managing parent.
Maybe the culture should wise up. “A fool and his money are soon parted,” as the proverb goes. Or a boob and her boobs, as the case may be?
Cancer Screenings
Welch et al survey the costs and benefits of mass (not symptomatic) cancer screening, highlighting overdiagnosis of breast, prostate, thyroid, skin, and lung cancers, and colon precancers. Again, they emphasize that they are not talking about getting screened when you have symptoms; that is a Good Thing (TM). They are talking about mass screenings for early detection of lethal cancers that we can actually prevent from killing you — a very low-prevalence problem.
Persistent inferential uncertainty pervades these screenings. It looks like they work, but very rarely. So a lot of people probably would not choose to pay the costs in anxiety and follow-up if they knew the probable benefit. But it seems (I think) perverse incentives combine with bias and error to drive demand for testing anyway. Much of the bias and error have to do with information asymmetry.
Here I should acknowledge again that there is more excellent work in this realm than I can possible cite, and especially that a currently more widely known iteration of this message comes from Vinay Prasad and his colleagues. (To be clear, though, Welch is also still currently publishing about this sort of thing, e.g., in the NEJM in 2021.) Like Welch et al, Prasad argues that we should hold cancer screening proponents to a higher evidentiary standard — proving that mass screenings reduce all-cause mortality. Not “convenient but faulty numbers (like five-year survival)” (Welch et al, p. 150).
Welch et al do a great job covering this terrain. But since their writing, health scholarship and activism on DCIS have changed the information women get about mammograms in many countries (up from zero mention of overdiagnosis in seven European countries’ pamphlets; p. 89). This is a huge win for women and informed consent. I’m going to briefly focus on other sources in exploring that example to illustrate some of the broader problems with medical MaSLoPP under conditions of persistent inferential uncertainty, before mentioning another set of screenings Welch et al omitted, and wrapping up with a brief summary of their recommendations and my criticism of them.
Case study: mammography and DCIS
As mentioned above, some of my favorite work in this critical arena comes from Dr. Susan Bewley, a renowned British evidence-based medicine reformer and King’s College London Emeritus Professor of Obstetric and Women's Health. In 2011 (the year Overdiagnosed was published), Bewley triggered a UK national review into breast cancer screening with an open letter in the BMJ: “I compared the NHS and Nordic Cochrane Centre leaflets and found that the NHS leaflets exaggerated benefits and did not spell out the risks.” Her letter and the resulting outcry triggered the Marmot Review, which Bewley interprets as validating her concerns:
the figures were something like: No screening (12 women with BC, 5 die of BC) vs Screening (15 women told they have BC, 4 die of BC) BUT the total numbers who die are still the same. So it’s outrageous that women are paraded or even believe ‘screening saved my life’ as (a) they might still go on to die, (b) they might still have lived if they waited, (c) they might be the 3 extra ‘cancer patients’ who’d never have presented. (Email, 21 Sept., 2023.)
But Dr. Annie Mackie, Director of Programmes for the UK National Screening Committee, wrote for the UK Health Security Agency blog in 2014 “The independent review on breast screening carried out by Professor Michael Marmot in 2012 concluded breast screening saves 1,300 lives in the UK each year and that the benefits outweigh the risks.” (Some comments on this blog are excellent.) It seems that different experts interpret the same scientific report as supporting opposing views on the wisdom of mass mammography, although that is a bit simplistic: Bewley and Mackie both support informed consent. But Bewley — and Marmot — are both apparently more concerned than Mackie that this consent be based on understanding of the risks as well as benefits.
Marmot spells out that there is a probable life-saving benefit (the one Mackie misrepresents as certain) to be balanced with the risks of overdiagnosis that Mackie does not specify:
But there is a cost to women‘s well-being. In addition to extending lives by early detection and treatment, mammographic screening detects cancers, proven to be cancers by pathological testing, that would not have come to clinical attention in the woman‘s life were it not for screening – overdiagnosis. The consequence of overdiagnosis is that women have their cancer treated by surgery, and in many cases radiotherapy and medication, but neither the woman nor her doctor can know whether this particular cancer would be one that would have become apparent without screening and could possibly lead to death, or one that would have remained undetected for the rest of the woman‘s life (p. 71).
This is an important uncertainty. And it often gets written out of the story when people reject it, contributing to biased information environments. For instance, Dawn Butler, a British Member of Parliament, thinks mass mammography — and follow-up major surgery — saved her life. Bewley thinks otherwise.
According to her account, Butler was diagnosed with “DCIS (Ductal Carcinoma in Situ) which is 0-1 stage breast cancer.” She had a 10-hour operation and was in intensive care for days after. “It took a lot of time for my normal bodily functions to return.” She understands the surgery as having been life-saving, saying that “when they removed the cancer cells, they’d found additional ones underneath. If they had been left untreated, it would have developed into a very invasive cancer.”
Bewley Tweeted, “Sadly, Dawn Butler seems to have been misinformed DCIS is not cancer, and it does not inevitably develop into invasive cancer… She is spreading misinformation despite her life-threatening huge operation & ITU stay.”
Bewley suggests Butler’s misinterpretation of that diagnosis and the recommended, radical treatment as life-saving reflect broader problems of how uncertainty aversion biases discourse on mass screenings in favor of potentially invisible, not entirely known/possible iatrogenic harms:
All women think they are a True Positive (as that's what they are told), and they don't have the opportunity to even understand the risks of being a FP before they start, let alone they have to find a psychological story to cope (see attached).
And Yes. There are lots of different things found - but our categorisation of a cell's ‘behaviour’ based on ‘imaging’ (whether Xray or histology) is probably wrong, and hard to follow (given we stick needles in that might cause neovascularisation/ transformation or spread) so we might not have full natural history. Mike Baum thinks we have the ‘linear progression’/ spectrum idea of pathology wrong, its a much weirder and systemic disease than that (which we don’t understand and is probably why screening doesn’t work). DCIS is thought to progress in about 10% of cases - so really dreadful to find it as it’s like a ‘time bomb’, excepting our breasts (and all of our organs) are ‘time bombs’ anyway. (Email, 21 Sept., 2023.)
Here Bewley points to another core element worth mentioning in the mammography false positive story, which scales up neatly to other false positive stories at least in medicine. That is the social reality element of what voices have approval to tell their stories, versus what stories don’t get told. “Particular care must be taken to look for and consider those untellable stories,” wrote Nathan Hodson and Susan Bewley in “Is one narrative enough? Analytical tools should match the problems they address,” J Med Ethics 2020; 0: 1-3.
So, in one view, Butler misperceived her own salvation, taking on life-threatening risks of probably unnecessary medical interventions and recruiting other women to do the same (element 1 above, risk perception). As Bewley wrote in “How should screeners respond to women’s distress about unexpected DCIS uncertainties?” - a 2011 Journal of Medical Screening letter to the editor with Miriam Pryke, Daphne Havercroft, and Mitzi Blennerhassett:
a diagnosis of DCIS distresses women…
When information about the uncertainties and rationale for treating DCIS is given at this late point [post-mammography] women are likely to realize that in attending screening they took a gamble whose implications had not been explained and to feel that being ‘railroaded’ into serious surgery on insufficient evidence is at best questionable, at worst unwarranted. Rather than therapy, which they were led to expect, it is a pre-emptive strike. As difficult as ‘Sophie's choice’. Hence the familiar distress.
In light of recent screening mammography research46 it would not be irrational to decline screening to avoid this predicament. Nor would it be irrational to decline treatment when mammograms and further tests have provided no additional information over and above what every woman already knows: that she may or may not, at some unpredictable time, develop life-threatening breast cancer…
All practitioners in this field must have faced dozens, perhaps hundreds, of women in this predicament. Their profound suffering is obvious, indeed expected, and entirely avoidable. Yet screeners continue to give inadequate preparatory information, women continue to have dubious ‘cancer’ diagnoses’ and researchers go on studying their distress… Well-intentioned people must now be sufficiently perturbed by the serious harm caused to tens of thousands of women to ask themselves if they can carry on ignoring it. It is time to correct pre-screening misinformation and end this institutional betrayal of women. What more does the NHS Breast Screening Programme need to know to stop the DCIS charade?
So the discourse has changed — because Bewley and others changed it — since Welch et al wrote, “you will never hear stories from people who were overdiagnosed, since it is impossible to know who they are.” There is wider recognition of the selection biases at work here, and alternative narratives like Bewley’s challenging simplistic ones like Butler’s “A Million Missed Mammograms” campaign. And there are stellar evidence-based risk communication efforts like the Harding Center’s, specifying:
A positive result from a mammography does not automatically mean that a woman has cancer. Mammography screening also detects preliminary stages of breast cancer, such as ductal carcinoma in situ (DCIS), which is characterized by abnormal cells in the mammary ducts that have not spread to other tissue (non-invasive). In some women DCIS remains harmless; in others it develops into an invasive tumor, which can be life-threatening [4].
As Welch et al write about the larger problem this case study illustrates:
the conventional wisdom tells us that… finding problems early saves lives because we have the opportunity to fix small problems before they become big ones… But the truth is that early diagnosis is a double-edged sword. While it has the potential to help some, it always has a hidden danger: overdiagnosis — the detection of abnormalities that are not destined to ever both us (p. xii).
In the case of DCIS, we can’t know which it is any given case. A life-saving early diagnosis and radical intervention; or (most likely) an unnecessary, risky, and disfiguring one. The rarer the problem (like preventable death from breast cancer), the more persistent the inferential uncertainty, and the riskier the secondary screenings, the more likely it is MaSLoPP backfire and endanger the very thing they’re trying to protect — in this case, women’s health. But there is no mathematical solution to this mathematical problem born of the inescapable accuracy-error trade-off. There is no single threshold at which mass mammography makes sense.
A lot of authorities have struggled to construct one anyway. But they can’t keep their story straight, because these lines are arbitrary and interpretive. Reasonable women might opt for or against mammography based on the available evidence. So why should guidelines tell them what to do?
Ok, I’m a dichotomaniac, myself. There is probably something between guideline recommendations as a directive and informed consent as an interpretive puzzle. But I’m not sure what, in practice, that something is.
Similarly, there is probably something between buying a false thresholding solution to the accuracy-error dilemma, and throwing up your hands because the dilemma is inescapable. Welch et al seem to suggest there is at least a better solution to the accuracy-error dilemma than the status quo. “I believe we could reduce the problem of overdiagnosis (as well as reduce false alarms) yet still preserve the death benefit if we were willing to look less hard for breast cancer” (p. 89). They propose an RCT comparing current practice with “a more conservative one: calling a mammogram suspicious for cancer (undertaking a biopsy) only if the detected abnormality could plausibly be felt (a size, say, greater than one centimeter)” (p. 89; also in JNCI). It might make sense to do a survey experiment in cases like this before running an RCT, to establish whether the RCT results would matter to the people ostensibly deciding the matter.
A Neglected Space: Mental Health
While adding gestational diabetes to Welch et al’s list was a matter of reading current medical news and noticing a new-ish threshold change case study for the pregnant women they covered well, adding mental illnesses is a matter of highlighting a space it seems the authors missed altogether. I read this primarily as a product of the split between psychiatry and the rest of medicine. In brief, there are big increases in screening for many mental disorders, and these screenings are MaSLoPPs because the outcomes we really want to avoid (e.g., suicide) are very low-prevalence. Anxiety and depression are usually the big two mental disorders:
Anxiety: The U.S. Preventive Services Task Force — an independent expert panel that reviews peer-reviewed literature to make preventive medicine recommendations — in 2022 recommending all adults under age 65 be screened for anxiety. (Their 2023 recommendation does the same.) But critics have long suggested that psychiatry increasingly pathologizes normal and sometimes adaptive emotions like anxiety, and that net harms may result from common pharmacological treatments.
Depression: Similarly, despite the best available evidence not establishing the intervention would cause more benefit than harm, numerous authorities have recently recommended more depression screening for a variety of groups including (e.g., in the U.S. in 2016) the general adult population and especially pregnant women. It’s worth noting that maternal use of common antidepressants appear to risk serious harm to pregnancies and offspring — risks that many dismiss without evidentiary basis.
Proposed Solutions
Welch et al wrap up the problem in a series of proposed solution chapters entitled “Get the Facts,” “Get the System,” and “Get the Big Picture,” followed by their conclusion, “Pursuing Health with Less Diagnosis.” They’re geared toward helping people make better individual decisions. This is a reasonable goal considering that individual people who may wish to avoid overdiagnosis harms are the book’s main audience, and also the main target audience of much relevant science communication.
Yet, these types of solutions are likely to be inadequate Band-Aids on the gaping wounds of incentives and biases driving overdiagnosis, as Welch et al so persuasively describe. Systemic reforms impacting incentive structures and working checks against common biases seem more likely to mitigate the problem in a big way. But systemic reform of, e.g., the American healthcare system is notoriously difficult.
In other words, maybe we are relatively powerless against systemic sociopolitical predation on one hand, and our own ignorance on the other. In which case, maybe identifying the problem and how individuals can fight it themselves — in effect, playing “hide and seek” from the predator instead of putting it in a cage — is the best we can hope to do. For now.
But maybe this is also a behavioral science problem with possible behavioral science solutions. While corporate and cognitive biases have driven behavioral scientists themselves to often favor i-frame reforms where s-frame ones would be better, say Chater and Loewenstein, these are at least somewhat identifiable distortions we can work to mitigate. Regulation, then, is part of the answer:
But where should the line be drawn on regulation? The behavioral and brain sciences won’t answer this question. The public, through normal democratic processes, must balance freedom-to-choose and freedom-from-temptation (or addiction). But behavioral insights should inform this debate, for example, regarding the power of visceral impulses (hunger, thirst, sex, pain, etc.) which can overwhelm a person’s attention and drive behaviors that may not align with their long-term interests (Critchley & Harrison, 2013; Loewenstein, 2006)…
Exploitation arises, too, from cognitive rather than motivational vulnerability. Products can be misleading and overly complex; advice can be distorted by conflicts of interest (see Table 2). Drawing the line between acceptable marketing (e.g., legitimately putting goods and services in a good light) and malpractice cannot, again, be resolved by scientific evidence – it is political choice to be made by the electorate and its representatives. Here too, insight from the behavioral and brain sciences should inform such deliberations. For example, if product complexity is too great for people to make stable choices (or assess which products are appropriate for which people or purposes), this “sludge” may bamboozle consumers into make choices against their own interests (Sunstein, 2020; Thaler, 2018; Thaler & Sunstein, 2021). Similarly, the fact that people largely discount disclosed conflicts of interest (Loewenstein, Sah, & Cain, 2012) should raise alarm bells for regulators relying on mandatory disclosure (e.g., Loewenstein et al., 2014). If privacy disclosures are demonstrably incomprehensible, they clearly cannot usefully inform choice (p. 17).
It’s a complex world, and medical care making people sick is a complex problem. Part of its complexity is systemic and needs to be addressed on that level. Because when we talk about overdiagnosis, we’re talking about informed consent; and when we talk about what information is needed to enable informed consent — and what, conversely, constitutes misinformation — we’re talking about political interpretations and actions. Reengineering the politics of incentives shaping medical information to combat common monetary and cognitive distortions — that’s a prescription for systemic change that the substance of Overdiagnosis supports, even as the book doesn’t take the logical next step to make it.
This is really interesting and lots to respond to. But I'll start right at the top. Unless you adhere to a very stringent definition of rationality (maximizing EV or EU) there's nothing irrational about playing the lottery. It just says you like long-odds bets with extreme positive outcomes. Here's my analysis
On the Optimal Design of Lotteries, https://www.jstor.org/stable/2554972