
Links 07/10
What I've been reading at the intersection of health and methods


Not again. More than a month without a post. Once more, life changes kept me busy: The new love that led me away from Berlin didn’t last, so I came home. Reuniting with old friends, reestablishing my home, and reconnecting with my son’s father have brought a comforting sense of stability back to my life. It’s a relief to be back in familiar surroundings, where I have a room of my own and can return to my work. But of course we have changed, this place, my family, and me: the windowbeds that went from green to brown in our absence got a much-needed makeover with help from my mom and stepdad visiting from North Carolina. My son takes center-stage this summer, while he’s briefly still three (and we’re finagling to get his daycare spot here back). And I’m expecting a new Wilde Thing. Now for some neglected tabs…

***
Statistical significance testing misuse and unclear causal logic in Neonatology
Necrotizing enterocolitis (NEC) is a rare, horrific, and potentially lethal intestinal inflammation and infection to which premies are especially vulnerable (I wrote about it previously here). A recent Neonatology article claims “The incidence of NEC was significantly lower during COVID-19 pandemic compared to the prior period (1.43 vs. 1.94%, p 0.037), but not the incidence of surgical NEC. The crude risk ratio of developing NEC during COVID-19 pandemic was 0.74 (95% CI: 0.55-0.98)” (“The Incidence of Necrotizing Enterocolitis and Late-Onset Sepsis during the COVID-19 Pandemic in Sweden: A Population-Based Cohort Study,” by Elena Palleri et al, Neonatology, 121(3):336-341, Epub March 5, 2024).
Statistical significance thresholding —> hyped claim
The upper bound of the confidence interval here is nearly 1; the statistical significance is borderline. And the effect size — with the incidence of NEC dropping from 1.94% to 1.43% — is about half a percentage point ( .51%). The authors’ representation of this finding as “significantly lower” thus exemplifies the “hyped claims” end of the statistical significance testing misuse spectrum against which scientists have risen up.
Similarly, the authors report “The incidence of late-onset sepsis with positive culture was also declined [sic] during COVID-19 (3.21 vs. 4.15%, p value 0.008).” The statistical significance here is not borderline, but the effect size in reality remains quite small — less than a percentage point.
The authors then conclude “While we found significant reduction in the incidence of NEC and culture-positive late-onset sepsis during the COVID-19 pandemic, the number of extremely preterm births was unchanged.” It’s not clear these infection reductions are practically significant. We’re dealing with <1% reductions in very rare but serious events. Maybe they are practically significant; maybe they aren’t. The methodological point is that we should be focused on that question, not on statistical significance.
It’s also not clear, in the case of the NEC reduction, that the finding reflects a real effect. It reflects a possible one. As always, we need to know something about causality to know if we care about what may or may not be going on here.
Causal logic
The authors attribute the changes to “pandemic restrictions in the NICUs.” We need to know if this means pandemic restrictions in the NICUs versus pandemic restrictions in society at large. If it’s the former, great: Maybe NICUs can extend pandemic restrictions post-pandemic to keep serious premie infection rates that little bit lower. If it’s the latter, everyone is out of luck: NICUs can’t bring back societal pandemic restrictions to marginally (NEC) or minimally (late-onset sepsis) lower these rates.
To their credit, the authors drew a DAG “to identify possible confounders that may induce noncausal association between COVID restrictions and NEC. The DAG was used for selection of covariates to include in the final model.” And they published it (see “Supplementary Material: Direct [sic] Acyclic Graph”).
However, the causal logics represented in the graph don’t appear to have anything to do with Covid restrictions in the NECs. This may be part of the phenomenon of dummy DAGs, DAGs that appear in papers because of increasing expectations that DAGs will appear in papers, but that do not really represent the full thinking-through of causal logic that they are supposed to.
Because they don’t do that job, they don’t help us disambiguate between causal components of Covid restrictions inside NICUs (e.g., fewer visitors to the ward) and Covid restrictions in the world at large (e.g., social isolation in general). If we want to know if there’s a causal effect, it would be good to first get clear on what exactly we want to know if there’s a causal effect of. If it’s the former, we need to consider the latter as a confound, and vice-versa.
One thing some evidence suggests has a causal effect lowering NEC: Probiotics. Unsuprisingly, sensitivity analysis excluding infants who got probiotics (Table 2) made the NEC effect lose statistical significance. If probiotics might work to lower serious infection rates (and/or mitigate serious infection outcomes like need for surgery), and this is an intervention we can actually control in NICUs — then why not give all the babies in the NICU probiotics, and see what happens to infection rates? Or: Why focus on a question about the causal effect of ambiguous Covid restrictions that you can neither disambiguate nor control, when you could focus on a question about a causal effect of something NICUs could do tomorrow to prevent harm?
***
Statistical significance testing misuse and beating the COVID-19 vaccine consensus drum
The consensus narrative about Covid vaccines is that they’re proven safe, and people who don’t believe that are silly, misinformed, corrupt, stupid, dangerous, and/or wrong. The reality is more complex: Different subgroups incur different risks (e.g., vaccine myocarditis in young males), and the evidence is incomplete and open to interpretation. In a political game of rhetoric over substance, medical and public health messaging tends to ignore the latter and treat real potential concerns as misinformation — in this context as in others.
Take, for example, “Coronavirus Disease 2019 (COVID-19) Vaccination and Stillbirth in the Vaccine Safety Datalink,” by Denoble et al, in Obstet Gynecol, June 6, 2024, online ahead of print.) The authors note:
Coronavirus disease 2019 (COVID-19) vaccination is recommended in pregnancy to reduce the risk of severe morbidity from COVID-19. However, vaccine hesitancy persists among pregnant people, with risk of stillbirth being a primary concern.
They perform “a matched case-control study in the Vaccine Safety Datalink (VSD)” to assess the relationship between Covid vaccination and stillbirth from Feb. 2021- Feb. 2022. Their analysis suggests there is a substantial possible relationship where one would expect an effect for most interventions if one existed — in closer temporal proximity to the intervention:
In the matched analysis of 276 confirmed antepartum stillbirths and 822 live births, we found no association between COVID-19 vaccination during pregnancy and stillbirth (38.4% stillbirths vs 39.3% live births in vaccinated individuals, adjusted odds ratio [aOR] 1.02, 95% CI, 0.76-1.37). Furthermore, no association between COVID-19 vaccination and stillbirth was detected by vaccine manufacturer (Moderna: aOR 1.00, 95% CI, 0.62-1.62; Pfizer-BioNTech: aOR 1.00, 95% CI, 0.69-1.43), number of vaccine doses received during pregnancy (1 vs 0: aOR 1.17, 95% CI, 0.75-1.83; 2 vs 0: aOR 0.98, 95% CI, 0.81-1.17), or COVID-19 vaccination within the 6 weeks before stillbirth or index date compared with no vaccination (aOR 1.16, 95% CI, 0.74-1.83).
This wide confidence interval suggests up to a possible 83% increase in stillbirth within 6 weeks from Covid vaccination. The absolute risk remains quite small. And the effect could also go the other way.
The point is that we don’t know. These data don’t tell us. So reasonable, well-informed pregnant women could well make different, valid choices about this. E.g., if you can mask and isolate, why take the possible substantial stillbirth risk of maternal Covid vaccination during pregnancy?
The authors, however, say “No association was found between COVID-19 vaccination and stillbirth. These findings further support recommendations for COVID-19 vaccination in pregnancy.” This is statistical significance testing misuse in the service of promoting the preferred narrative of powerful social and political networks — in this case, the Covid consensus.
The technically correct statement would be “no statistically significant association.” The better statistical form would be to interpret the full confidence intervals. The better scientific form would be to consider causality in the whole question (e.g., the possibilities of effect dilution when pooling across trimesters and outcomes without respect to when the vaccination occurred). And the better practical form would be to recognize that the recommendations make something black-and-white and one-size-fits-all out of scientific evidence that is ambiguous, open to interpretation, and the meaning of which probably depends to some extent on people’s specific circumstances and preferences.
***
Another hyped effect and I2 misinterpretation in Acta Obstet Gynecol Scand
In “Association between postpartum depression and postpartum hemorrhage [PPH]: A systematic review and meta-analysis” (Acta Obstet Gynecol Scand, . 2024 Jul;103(7):1263-1270), Sheng et al tout an effect of postpartum hemorrhage on postpartum depression risk. But their analysis shows a confidence interval that nearly hugs one, suggesting there may not be an effect at all: “Women with PPH were at increased risk of PPD compared with women without PPH (OR 1.10; 95% CI 1.03-1.16), and heterogeneity was low (I2 = 23%; τ2 = 0.0007; p = 0.25).”
In the same sentence, they make a typical meta-analytical mistake interpreting I2. As University of Birmingham Biostatistics Professor and Chief Statistics Editor for the BMJ and BMJ Medicine Richard Riley BSc, MSc, PhD, writes regularly on Twitter/X, it’s a common misconception that I2 estimates between-study heterogeneity. In reality, “I-squared measures the proportion of total variability due to between-study heterogeneity.” Just as we must remember there are many possible sources of uncertainty in statistical estimates (not just what gets quantified in confidence intervals), so must we remember there are many possible sources of variability in studies in meta-analyses.
Riley continues:
The actual statistical measure of between-study heterogeneity is the estimate of between-study variance (tau-squared) from a random-effects meta-analysis… I-squared measures the proportion of the total variability that is due to between-study heterogeneity. As such, it is highly influenced by the size of the studies (within-study variability), not just the size of between-study heterogeneity.
***
RSV maternal vaccine trial stopped early due to safety concerns
Preterm birth occurred in 6.8% of the infants (237 of 3494) in the vaccine group and in 4.9% of those (86 of 1739) in the placebo group (relative risk, 1.37; 95% confidence interval [CI], 1.08 to 1.74; P=0.01); neonatal death occurred in 0.4% (13 of 3494) and 0.2% (3 of 1739), respectively (relative risk, 2.16; 95% CI, 0.62 to 7.56; P=0.23), an imbalance probably attributable to the greater percentage of preterm births in the vaccine group. No other safety signal was observed. (“RSV Prefusion F Protein–Based Maternal Vaccine — Preterm Birth and Other Outcomes,” Dieussaert et al, N Engl J Med, March 13, 2024, Vol. 390, No. 11).
It’s worth noting that the neonatal death effect goes up to a substantially larger effect size than the preterm birth effect observed here. It’s hypothesized but not known that the latter accounts for the former. It’s also possible that prematurity contributes to but does not fully explain the massive possible neonatal death effect — i.e., that the vaccine caused some preventable neonatal deaths through reasons other than prematurity.
***
Statistics misuse in the Lucy Letby trial
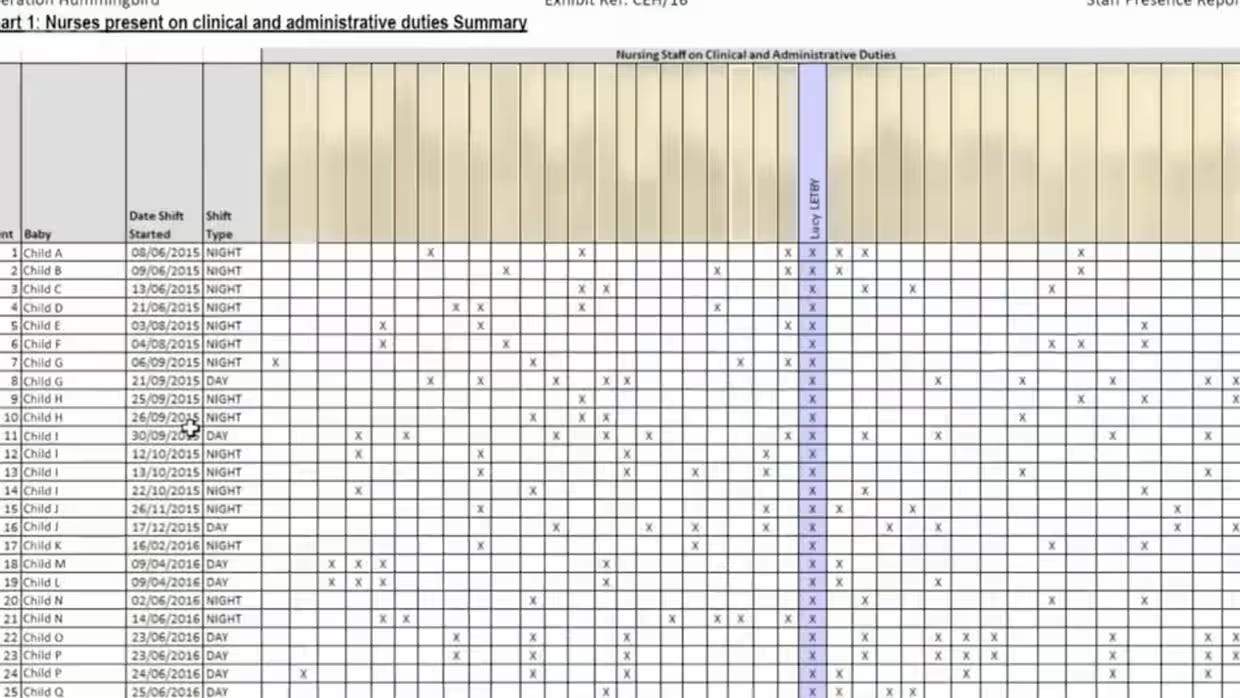
The Guardian has published a clear and informative article on statistics misuse in the Lucy Letby neonatal nurse murder trial (“Lucy Letby: killer or coincidence? Why some experts question the evidence,” Felicity Lawrence, July 9, 2024). It features this image, labelled “A chart issued by the police, shown to the jury as evidence of Letby’s constant presence when incidents occurred. Photograph: supplied,” and states: “A key plank of the prosecution was that it was always Letby who was there when the babies collapsed or died unexpectedly.”
Correlation is not causation. As University College London statistical science professor John O’Quigley told The Guardian: “ ‘all the shift chart shows is that when Letby was on duty, Letby was on duty.’ ”
In addition, the police misrepresented the full picture here, omitting “six other deaths in the period with which Letby was not charged.” Not only were they omitted from the chart, but the jury was not told about them.
Professor John Ashton, a former whistleblower on another cluster of English baby and maternal deaths, suggested people want someone to blame in these situations. But real causal explanations more often involve complex systemic problems and numerous contributing factors.
Ashton told The Guardian:
You don’t need a serial killer to account for what happened at Chester. Disasters, and this was a disaster, generally happen as a result of the convergence of a number of factors … We’re talking in Chester about system failure – it was a hospital that was not well run, that had ambitions beyond its capability, that had problems with clinical governance and environmental problems.
The arguments about Lucy Letby herself boil down to the fact that circumstantial evidence, and statistical and expert witness evidence that I believe was seriously flawed, were presented to the court.
In an interview with Sarah Scire for Nieman Lab, Rachel Aviv points out another error in the Letby shift / suspicious events chart:
" 'this diagram actually had an error: for one of the suspicious events, it showed Letby working a night shift, when she was actually working a day shift, so there should not have been an X by her name. Even after this discrepancy had been addressed at trial, the police still used that diagram. This is just one example of why the work product of the communications team for a police force should not be presented and treated as if it were journalism.' "
- https://www.niemanlab.org/2024/05/impossible-to-approach-the-reporting-the-way-i-normally-would-how-rachel-aviv-wrote-that-new-yorker-story-on-lucy-letby
Aviv was interviewed because she wrote the seminal New Yorker article on the Letby case (https://www.newyorker.com/magazine/2024/05/20/lucy-letby-was-found-guilty-of-killing-seven-babies-did-she-do-it). The article was blocked to UK online readers during her recent retrial for legal reasons (https://theconversation.com/why-the-new-yorker-blocked-uk-website-readers-from-its-lucy-letby-story-an-expert-explains-230255).