


Beyond Fienberg: How Mass Screenings Work
A first attempt at diagramming their causal mechanisms

tl;dr: Mass screenings for low-prevalence problems like polygraph programs for spying don’t just fail on accuracy-error. They also shape strategic behavior and information environments, often in unpredictable ways. Same goes for other programs that share the same mathematical structure across diverse areas such as security, medicine, and education/scientific publishing. This post sketches a causal model to help think about those effects.

When we talk about tests, from forensics to medicine, we usually talk about accuracy. That was Stephen Fienberg’s focus, for instance, when he co-chaired the National Academy of Sciences’ report on polygraph screening programs. But that focus left out critical causal mechanisms — how mass screenings change behavior and information environments. This post presents a first sketch of those mechanisms.
The graph above, a DAG (directed acyclic graph), assumes one-off testing with no feedback loops. Like all models, it is wrong but may be useful. The wrong part: Sometimes, it’s reasonable to assume that test outcome doesn’t influence future tests; but often, it’s clearly not. The useful part: It illustrates the classic accuracy-error trade-off implied by a one-off application of Bayes’ rule.
Or at least it would, if we complicated the picture by drawing out the two subcomponents of each mechanism, which might be viewed as two separate causal mechanisms:
Classification
Accuracy (true positives and true negatives)
Error (false positives and false negatives)
Strategy
Adversarial avoidance, aka evasion (bad people/stuff evades detection)
Compliant avoidance, aka deterrence (rule-abiding behavior improves)
Information
Elicitation (people volunteer more information in the interaction)
Suggestion (the test interaction itself shapes social norms and expectations)
A future post will draw that out, but for now let’s keep it simple.
The graph below, a DCG (directed cyclic graph), assumes iterative testing and/or feedback loops instead. I wrote about the difference and why I think even one-off polygraph testing requires DCGs in this post.
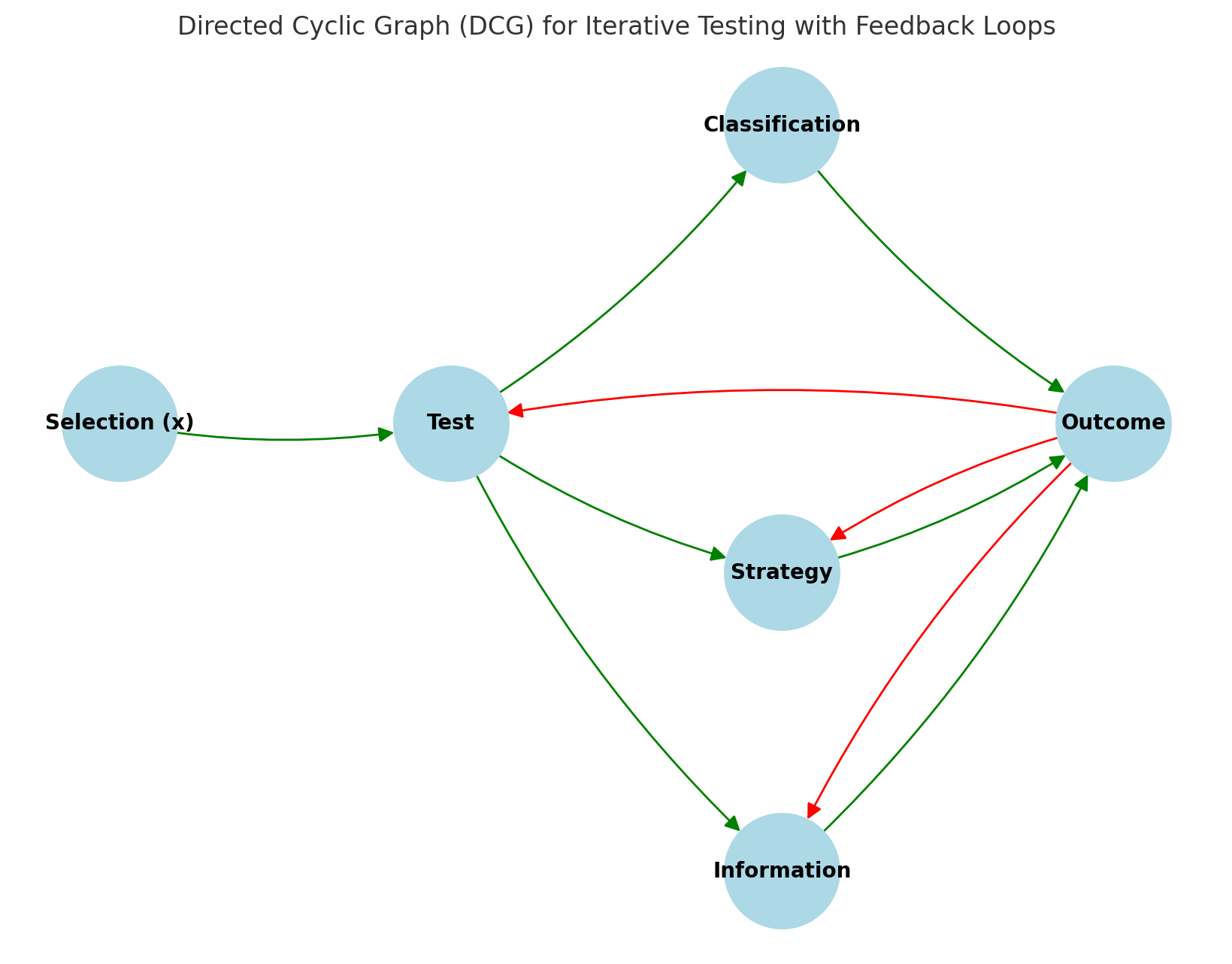
Again, even in one-off testing scenarios, if there are feedbacks, we need DCGs. (Feedbacks are indicated here with red arrows.) If we get this wrong, we risk analyzing screening programs in ways that ignore crucial effects — as Fienberg and NAS did polygraph programs. The difference between a one-off DAG and an iterative DCG is not just technical. It centrally shapes how we think about the empirical, real-world effects of policies.
Here is a bit of interpretation of the DCG, which I think is the more interesting graph: X captures the idea that something selects into the test (e.g., external criteria, policies, or prior screening stages). Outcome may feed back into test, reflecting the iterative nature of Bayesian updating. For instance, a previous mammogram may have resulted in a biopsy that got marked with a metal bit that future mammograms will pick up to know that spot has already been investigated further. Outcome feeds into strategy, modeling strategic adaptation — where people or institutions learn from past test outcomes and adjust their behavior accordingly. Outcome feeds into information, modeling how the information environment (a famously hot mess to model) may affect perceptions, policy, and even the avowedly neutral, scientific classification process itself. Test feeds into strategy, modeling how the fact of the test can incentivize strategic behavior even before the test interaction itself.
No one has seen it yet and this could be wrong (please give me feedback). In particular, I had classification feeding into strategy thinking, for instance, people could learn about false positives from security screenings and engage in evasion in response. But I have to wonder how common such preemptive evasion by good actors really is, and so whether it’s worth modeling. (I removed it.)
There is theoretical and empirical work to be done figuring out who uses what programs in what ways, when; how to use that possibility to improve outcomes (including how some people and organizations doubtless already do); and which statistical paradigm therefore best applies for analyzing and possibly improving program efficacy (e.g., Fienberg’s straight one-off application of Bayes’ rule in the NAS polygraph report, versus Bayesian search).
There is also naturally some stuff that gets left out of these pictures, pictured in the incomplete sketch below. For instance, there are three relevant continua to consider — the validation problem (can we solve it?), whether the test is compulsory or voluntary, and the truth underpinning the binary test classifications (how much information are we losing and does it matter?). Where are common cognitive distortions likely triggered (e.g., the base rate bias by the accuracy-error trade-off)? And how do the other causal mechanisms affect test accuracy (e.g., strategic behavior in security contexts)?

Again, my critique of Fienberg is moored in an appreciation for his focus on the implications of probability theory and the pervasiveness of cognitive bias. Both facets of his work also bear extension in terms of looking at how Bayes’ rule implies other trade-offs in addition to accuracy-error. Specifically, when we apply it in iterative testing contexts, as many of these are, the Bayesian search paradigm may be a more appropriate one to apply, and it invokes different trade-offs: (1) exploitation vs. exploration (where to search next), (2) certainty vs. flexibility (how much weight to give priors), (3) computational efficiency vs. precision (how exact updates should be), (4) false confidence vs. false skepticism (how quickly models adapt), and (5) predictability vs. gaming vulnerability (adversarial manipulation risk). A future post will synthesize some literature on this paradigm and these trade-offs. (I haven’t even started gathering readings yet; send help and papers.)
It’s really important to figure this out eventually. Because, if mass screenings often operate in an iterative mode, then applying Bayesian search instead of one-off Bayes’ rule shifts our focus. Instead of just asking “How accurate is this test?” — we also have to ask: “How does information accumulate? How does uncertainty change? How does the test itself shape future behavior and decision-making?” These are different trade-offs entirely. If policy analysis writ large is based on the wrong trade-offs, we need to change that.
For now, let’s just run through what these causal mechanisms mean in some examples, with reference to these newly central trade-offs as needed...
Test Classification: Invoking the Accuracy-Error Trade-off
The screening claims to detect an underlying reality, like deception via physiological responses (polygraphs), child sexual abuse material via AI mass scanning of digital communications (Chat Control), early cancer via mammography or PSA testing or any number of other medical tests, student use of AI in writing and researcher lack of trustworthiness in scientific publishing. But these tests rely on imperfect proxies for the underlying thing of interest. That’s what makes these programs share a common mathematical structure as signal detection problems. It’s also what limits their accuracy so that even highly accurate tests for rare problems, applied at a mass scale, will tend to produce large numbers of false positives.
Under certain conditions, mass screenings for low-prevalence problems still make sense. When it’s possible to disambiguate true from false positives through further testing, secondary screening doesn’t do net harm, and you can meaningfully change the outcome through identifying and treating cases, then this type of program can offer huge benefits to society. Success stories of this type include screening all pregnant women for HIV and hepatitis B. But when the problem is rare, inferential uncertainty persists after mass screening, and secondary screening is costly (in various ways), the programs risk doing net harm because of the huge numbers of false positives they produce — while also taking finite resources away from addressing the problem in other ways.
While crucial to account for in the causal diagram, this type of Bayesian backfire effect is uni-directional — in a world of feedback loops. People are active participants in their environments, including these screenings! For one thing, they might change their behavior in response to them…
Strategic Behavioral Effects: The Naughty and the Nice
Mass screenings don’t just classify people like inert entities. They also provoke strategic responses. Some actors try to evade detection, sometimes undermining the system entirely…
The Naughty
When they do it in a way that undermines the desired outcome at the system level, it’s sometimes called adversarial avoidance (as opposed to compliant avoidance), evasion or circumvention (as opposed to compliance), or using countermeasures.
The most obvious examples are negative value-valenced ones, like dedicated attackers actively using sometimes extreme measures to beat security screenings (e.g., spies learning purported polygraph countermeasures, pedophiles and drug dealers using purportedly safer communication channels). In the medical realm, patients may game the system to get access to controlled substances (e.g., opiates or amphetamines) or benefits (e.g., welfare fraud). In education/research, students and researchers may modify their work to evade AI plagiarism detection or manipulate “trust markers” (links) for publication.
But we can also imagine positive value-valued manipulation of this type. Democratic activists may game mass surveillance to oppose oppressive regimes (e.g., dissidents in Iran using Tor). Sicker patients may game diagnostic thresholds to help correct for doctors not doing the right Bayesian updating in their cases (e.g., select out of clinical encounters with higher transaction costs and stricter threshold enforcement, into telemedicine). Students with worse educational backgrounds or support resources may opt to improve their work using LLMs while trying to remove any possible tell-tale signs, learning more in the process.
The general point is that bad actors may just get better at hiding in response to screening measures — except we may not want to call them bad, and they may be gaming the system in other ways than hiding (e.g., venue changes). This form of strategic adaptation can lead to arms-race dynamics, where screening improvements drive increasingly sophisticated evasion techniques.
Pha. Sounds like a lot of work and confusion. Why might we still want to bother with mass screenings for low-prevalence problems, when strategic behavior can so obviously undermine their efficacy?
The Nice
Maybe because screening can also encourage rule-abidingness — sometimes in ways that benefit society, sometimes in ways that reinforce coercive norms. This is called compliant avoidance (as opposed to adversarial avoidance), compliance (as opposed to circumvention or evasion), and best known at the system level as deterrence.
This is about enhancing rule-abidingness through both selection and behavioral effects (a distinction not currently shown in the diagram). In security, polygraphs may deter spies from applying for classified jobs in the first place, or thugs from applying for police jobs; and they may deter security professionals from breaking the rules once they’re hired. In medicine, routine screenings may pressure people to adopt healthier behaviors. If you know your gyn is going to want to test you for cervical cancer every few years, then maybe you’ll think twice before risking cancer-causing HPV infection from unprotected sex. In education/research, maybe students are less likely to copy and paste AI-generated content if they think they may be caught, and researchers who know their article is going to be screened with AI for “trust markers” are less likely to try to game peer review by going to their buddies for a perfunctory critique.
But baby, it’s a topsy-turvy world — and just as the naughty is not always naughty, so too the nice is not always nice. Mass surveillance might deter dissent and suppress free speech — degrading the quality of discourse. In academia, fear of being falsely flagged by AI screenings whose algorithms key on what most people argue might lead researchers to avoid expressing contentious views or studying polarized topics, stifling critique thought and degrading the quality of science. Deterrence is not always good; it depends on what is being deterred.
Information Effects: Two Directions
Screenings can also have information effects that flow in both directions — from the person being screened and the person/entity doing the screening.
Elicitation
When the person being screened offers up information during the process, that can be termed elicitation (as opposed to avoidance in the strategic behavioral context) or the bogus pipeline effect (as if the screening were a direct pipeline to the truth). We might assume, again, that this effect has a positive valence; but we don’t know that empirically and it may vary by case study.

For instance, in my dissertation research on polygraphs, my DID analysis of national police departments found that the programs may decrease women’s full-time sworn representation on police forces. One could imagine several possible causal mechanisms for such an effect. The most plausible in my estimation is that women’s higher average Agreeableness (a Big Five personality trait) may lead them to volunteer more negative information in adversarial interrogations (a “good girl” effect), even when they have not really done crime. (Maybe that comes at a cost to both police diversity and quality because it’s adding noise to the signal, maybe not; and maybe the disparity doesn’t even exist, we don’t know for sure. It was just a possible bias effect measured in a problematic analysis that didn’t make sense in relation to women’s widely documented lower rates of criminal behavior and polygraphs’ estimated police brutality-lowering effect from the same analysis.)
Similarly, health screenings that make people volunteer symptoms and seek additional care could create more overdiagnosis. The general point is that we shouldn’t assume elicitation is always a good thing. There are so many steps between reality, perceiving it, communicating that, and someone else perceiving the communication. So many steps! How does anyone ever communicate anything?!
But, sometimes, there is signal in the noise of that gargantuan effort, and it’s helpful to get it in screenings or however else we can. Of course we as a society want criminals to confess to their crimes (especially before we consider giving them special powers), patients to tell doctors what’s ailing them, and researchers to disclose conflicts of interest before publishing in scientific journals.
People, however, are so messy that we are not generally capable of one-way communication (stone-cold exes notwithstanding). Just as subjects may volunteer information in response to screenings, so too do administrators/organizations communicate information when they conduct them…
Suggestion
… And that information may not be what they think it is.
For instance, Rosenbaum & Hanson 1998 found the DARE program (Drug Abuse Resistance Education) had a small, short-term boomerang effect — increasing instead of decreasing drug use among suburban middle and high school students. Caveats apply: this was one just study of many that did not find such an effect, and DARE is an informational intervention and not a screening. Still, it’s a famous example of potential policy backfire and raises the question: What if some screenings backfire sometimes?
Generally, tests could accidentally encourage bad behavior by changing the information environment. One way this could work is by suggesting the behavior as a norm, making it seem cool/sexy (transgression doesn’t always code as badness), showing enforcement mechanisms to be flimsy, or creating perverse incentives. What if some scientists at the National Labs (or adjacent recruiters) would look at a DOE polygraph program to catch spies as evidence that you can get away with spying — because this is among the apparently best tools they have for catching it, and it’s widely viewed as pseudoscience? What if some high school English students would view use of plagiarism detection software as a sign that teachers can’t smell plagiarism, themselves?
In medical contexts, I am not sure if some forms of iatrogenesis should go here, or somewhere else in the diagram. What about cancer caused by mammography radiation, or cancer spread caused by mammography compression or needle biopsy? Does it make sense to think of these sorts of causes as informational, or is that just stilted, suggesting either maybe the biomedical world needs a different version of the general graph, or it should encode a physical iatrogenesis versus information iatrogenesis distinction?
Conclusion
The upper echelon of contemporary scientific discourse on mass screening programs focuses largely on concerns about accuracy and error, when it is not concerned with subgroup bias. The latter concern generally fails to grapple with the incompatibility of various common definitions of statistical fairness. Both fail to do science the best way we know how, by first diagramming causes and only then running statistical analyses. The reason for the error is simple: the causal revolution is relatively new.
Society still needs to know what the net effects of all kinds of programs are, preferably before implementing them on a mass scale. Diagramming causality like this should help us think about how to structure research to find out. Scary that we don’t know, cool that we can do better now.
Wait, what exactly do we not know again?
Questions for Future Research
RQ1: Beyond one-off testing — considering iterative testing effects

When does the one-off versus iterative paradigm apply? When, why, and how do we need to consider iterative testing effects? Does that really kick us into a Bayesian search paradigm? And what would that mean?
RQ2: Beyond test accuracy — considering additional causal effects
This causal modeling needs work and must come first, except first we need to know if we’re in one-off (DAG) or iterative (DCG) space.
RQ3: Beyond structural conditions — considering uncertainty
Then, multiverse policy analysis needs to be done to incorporate uncertainty more explicitly into quantitative estimates of possible program outcomes to help decision-makers assess program net effects.
RQ4: Beyond certainty about communicating uncertainty — considering risk literacy
Finally, we need to know how to tell people about risks and benefits in a way that empowers them to actually make better decisions based on our science. There is a possibility that people could encode quantitative estimates of hypothetical risk as relatively certain, lowering appropriate risk aversion (the Ellsberg paradox). The whole project should be translated into a free online risk assessment tool (something like this one I’ve been thinking about for a while) capable of testing whether that’s a problem.
This tool should eventually replace the Harding Center fact boxes of which I’m a huge fan as the new gold standard in risk literacy. They do a tremendous public service, but are methodologically obsolete because they don’t consider causality or adequately communicate uncertainty.
If we want to understand the net effects of mass screenings, we have to stop treating them as unidimensional tests — and start seeing them instead as interventions that shape behavior, information, and society itself. Causal diagramming help us see these dynamics. It doesn’t show moderating effects (h/t again Richard McElreath for pointing this out when he helped me draw my breastfeeding DAG two years ago), when powerful moderating effects are part of the argument. Still, it illustrates the main point: That the real question we need to ask isn’t just whether a screening works, but how it changes the world. Since that’s what we care about at the end of the day — and tests that detect problems can also create new ones.