


What to Expect When You're Expecting Experts to Not Know What to Expect
Probability elicitation, the uncertain consequences of tackling uncertainty aversion, and how Bayes might mean something else entirely for the dangerous structure

People are overconfident. Maybe it’s because that’s just how our silly monkey brains work. Maybe it’s because they get paid more that way. Maybe it’s because, deep down, you’re all just as insecure as me.
 Memedroid")
Experts — being people, too — often overestimate certainty due to common cognitive-emotional distortions, social and professional pressures, and the simple fact that researchers don’t usually ask them about uncertainties. Probability elicitation helps quantify uncertainty in expert interviewing, but is under-utilized in many fields. This post gives a brief overview of relevant sources and methods as well as challenges. Along the way, I accidentally fall into the abyss; but that’s ok, it’s Wednesday. (Happens every week.)
Probability or prior knowledge elicitation
This appears to be a huge field I should have known existed, having done graduate training in survey research methods in three departments, plus a field experiments summer school certification at ICPSR. How are you gonna do a power calculation for a field experiment without integrating some measure of uncertainty into what experts know about how big the hypothesized effect(s) might be, when you have enough uncertainty about that to do a field experiment in the first place?

Luckily, it seems other people have done a lot of the work for us here.
O’Hagan et al 2006 is the standard textbook (Uncertain Judgements: Eliciting Experts’ Probabilities; it seems to be here). The authors recommend five best-practice elicitation methods: quartile, roulette, tertile, probability, and hybrid.
Pick a method, any method
Quantile, tertile, and probability methods all ask experts to estimate key points in a distribution (e.g., 10th, 50th, and 90th percentiles). This is designed to avoid anchoring bias and otherwise minimize overconfidence. It has the disadvantage of asking people to think numerically instead of visually. These methods work best for continuous variables.
With the roulette method, you ask experts to distribute a set number of chips across bins representing possible variable values. Stack Exchange poster Glorfindel researched the trial roulette method for his masters thesis and makes a good case for it: the expert can move chips around after an initial placement, the probabilities must sum to one, and graphical methods seem to produce more accurate results than numerical ones (think Gigerenzer and Hoffrage). It also sounds fun. It works best for discrete variables and in-person interviewing.
But we need a quick and easy way to implement any of these methods…
Straight off the SHELF
O’Hagan, Emeritus University of Sheffield Statistics Professor, and University of Sheffield Statistics Professor and Head of School of Mathematical and Physical Sciences Jeremy Oakley developed the Sheffield Elicitation Framework (SHELF), a free elicitation templates and softwares package. Then Oakley collaborated with University of Nottingham engineering professors David E. (Ed) Morris and John A. Crowe to design the online tool MATCH to aid in probability elicitation in expert interviews (“A web-based tool for eliciting probability distributions from experts,” Environmental Modeling & Software, Volume 52, Feb. 2014, Pages 1-4, ISSN 1364-8152; it’s part of the MATCH project to improve UK medical devices).
Since it’s online, it works for remote meetings. Since it’s a GUI, it lets experts visualize and refine their estimates interactively. The European Cooperation in Science and Technology claims to maintain an updated list of relevant software solutions including this one “to encourage the practical use of different Expert Judgement methods” here. MATCH seems to be the field leader.
MATCH supports all five main elicitation methods. Roulette sounds fun, but won’t work for my upcoming meeting. It would be awkward to ask the experts to bring chips. Plus, I need to know how they would estimate the base rate of the problem of interest (how often does the rare badness occur?), the accuracy of the screening tool (how right or wrong could the people who stand to profit from hawking it be?), and the false positive/negative rates (how many cases could it wrongly flag or miss?). Those are continuous variables.
So another method of elicitation is a better (ahem) match. I would prefer the precision of the probability method. And one might hope that probability elicitation could still be graphical enough, with the right graphical user interface, to maximize accuracy. In line with that expectation, Palley and Saurabh Bansal 2017 report the results of eight experiments with 1,456 participants and 30,870 complete distribution judgments suggesting that “visual probability elicitation tools offered similar performance to quantile judgments, with each format holding a slight advantage according to different metrics.”
However, there are two problems with this: First, if you learn one thing from Kahneman, Tversky, Piattelli-Palmarini, etc. on human stupidity, it should probably be that we got 99 problems but a prior ain’t one. Average Bayesian statistical intuition tends to be quite poor.
Second, if you go take a look at the MATCH tool and select Probability mode on the bottom right, chances are, the equations that pop up will make your eyes glaze over faster than you can say “Bayes-d and Confused.” I’m not doing this to my collaborators. I may not have an IRB at the moment, but I have ethical standards.
Quartiles or tertiles it is.
Just add humans!

What is this? If you wanted to make asking people to talk about their uncertainty sound as complex and daunting as possible, could you come up with a better name for it than “probability elicitation”? I know we all need our specialized knowledge to sound very complicated in order to (maybe, someday) get paid for using it. But this is in the running for worst academickese ever.
MATCH doesn’t fare much better in terms of immediate comprehensibility. It’s great in theory, but I can’t imagine sending a human being to the tool during an expert interview without at least having given them a warning and simple instruction sheet to go with it in advance — lest their eyes glaze over and I lose them.
As Mikkola et al say in their recent literature on “Prior Knowledge Elicitation: The Past, Present, and Future”: “In practice… we are still fairly far from having usable prior elicitation tools that could significantly influence the way we build probabilistic models in academic and industry” (by Petrus Mikkola, Osvaldo A. Martin, Suyog Chandramouli, Marcelo Hartmann, Oriol Abril Pla, Owen Thomas, Henri Pesonen, Jukka Corander, Aki Vehtari, Samuel Kaski, Paul-Christian Bürkner, Arto Klami; Bayesian Analysis 19(4): 1129-1161, Dec. 2024).
Ok, so it’s not just me. These things are not road-ready. But we are on a journey, so what does this literature actually have to give practicing researchers right now? Practitioners who “often use rather ad hoc procedures to specify and modify the priors” (p. 1130)? Why does science always seem so unscientific at the top? Almost like it’s being done by human beings…
Interestingly, the authors note this is a possible reason for the current lack of road-ready probability elicitation tools. People would need to collaborate across statistical and algorithmic research, cognitive science, and human-computer interaction (not to mention survey methods) to build this stuff. But scientists have a:
long history of avoiding strong subjective priors in quest for objective scientific knowledge or fair and transparent decision-making. Audiences struggling to accept subjective priors in the first place are best convinced by maximally clear examples that leave no room for additional layers of complexity, such as prior elicitation procedures (p. 1135-6).
So we are left with survey research standards that largely leave uncertainty out of our measurements. On one hand, this looks like a next frontier for the methods reform set. The authors suggest it has similar sociopolitical importance: “If you are not choosing your priors yourself, then someone else is inevitably doing it for you…” (p. 1144). This resonates with Greenland’s criticism that researchers often privilege the preferred narratives of powerful sociopolitical networks in misinterpreting statistical significance test results and otherwise downplaying the salience of uncertainties in science.
On the other hand, there’s not a standard validation paradigm for different elicitation methods (p. 1147) and “we lack good metrics for evaluation” (p. 1148). So how exactly this stuff gets validated seems to be an open empirical question. (No wonder: earlier on, Mikkola et al presented a seven-dimensional prior elicitation hypercube. This apparently has the dual function of illustrating how other people are already setting your priors for you, while also showing why you should probably avoid dealing with setting them yourself if you ever want to do a comprehensible analysis and/or finish a job; see Figure 1, p. 1137.)
As with most of surgery and scientific research, the state of the art seems to be: Read a bunch of related literature and wing it. The only way to really learn how to do it well is by doing it. It would be great if we knew better what worked before trying it. But that’s not how the plumbing of reality gets fixed (or broken, as the case may be). Good luck with that brain surgery!
At least this may explain why ICPSR wasn’t teaching probability elicitation back in the day. It seems there’s not much of a method here to teach. As if that practical problem were not enough, probability elicitation is intertwined with utility elicitation, which is also problematic in its own ways…
A brief note on utility elicitation
How we value different possible outcomes (utility) shapes probability judgments. Kadane and Winkler suggest “elicited probabilities can be related to utilities not just through the explicit or implicit payoffs related to the elicitation process, but also through other stakes the expert may have in the events of interest” (“Separating Probability Elicitation from Utilities,” Journal of the American Statistical Association, Vol. 83, No. 402, 1988). In other words, people have interests that may color their perception and reporting.
For example, how much a woman fears an amniocentesis may color how she estimates the probability of fetal anomalies. How an expert values liberty versus security may color his estimates of surveillance effectiveness, whether through difficult-to-model possible causal dynamics like deterrence or through simple cognitive-emotional bias. So people’s probability estimates can be shaped by what’s at stake, suggesting probability and utility elicitation can’t be clearly separated.
This presents problems for probability elicitation. We don’t necessarily know people’s utility functions, and they can’t necessarily tell us what they are even if we ask them. There may also be difficult contextual dimensions involved in this asking and telling, like social desirability (e.g., a woman not wanting to say in front of her husband if she would or wouldn’t want an abortion in the event of a fetal anomaly) and power dynamics (e.g., an expert not wanting to say in front of his colleague or boss if their values differ). This starts to get into more classic survey research terrain, e.g., about asking people sensitive questions.
Maybe this helps explain why utility elicitation, like probability elicitation, seems to be mostly ignored by practitioners. The prenatal testing example recurs in “Utility Elicitation as a Classification Problem,” where Urszula Chajewska and Lise Getoor show this “simplified version of PANDA [prenatal testing decision analysis] model (courtesy of Joseph Norman and Yuval Shahar, Stanford’s Section on Medical Information)” (Proceedings, Papers from the 1998 AAAI Spring Symposium, Interactive and Mixed-Initiative Decision-Theoretic Systems, p. 33):
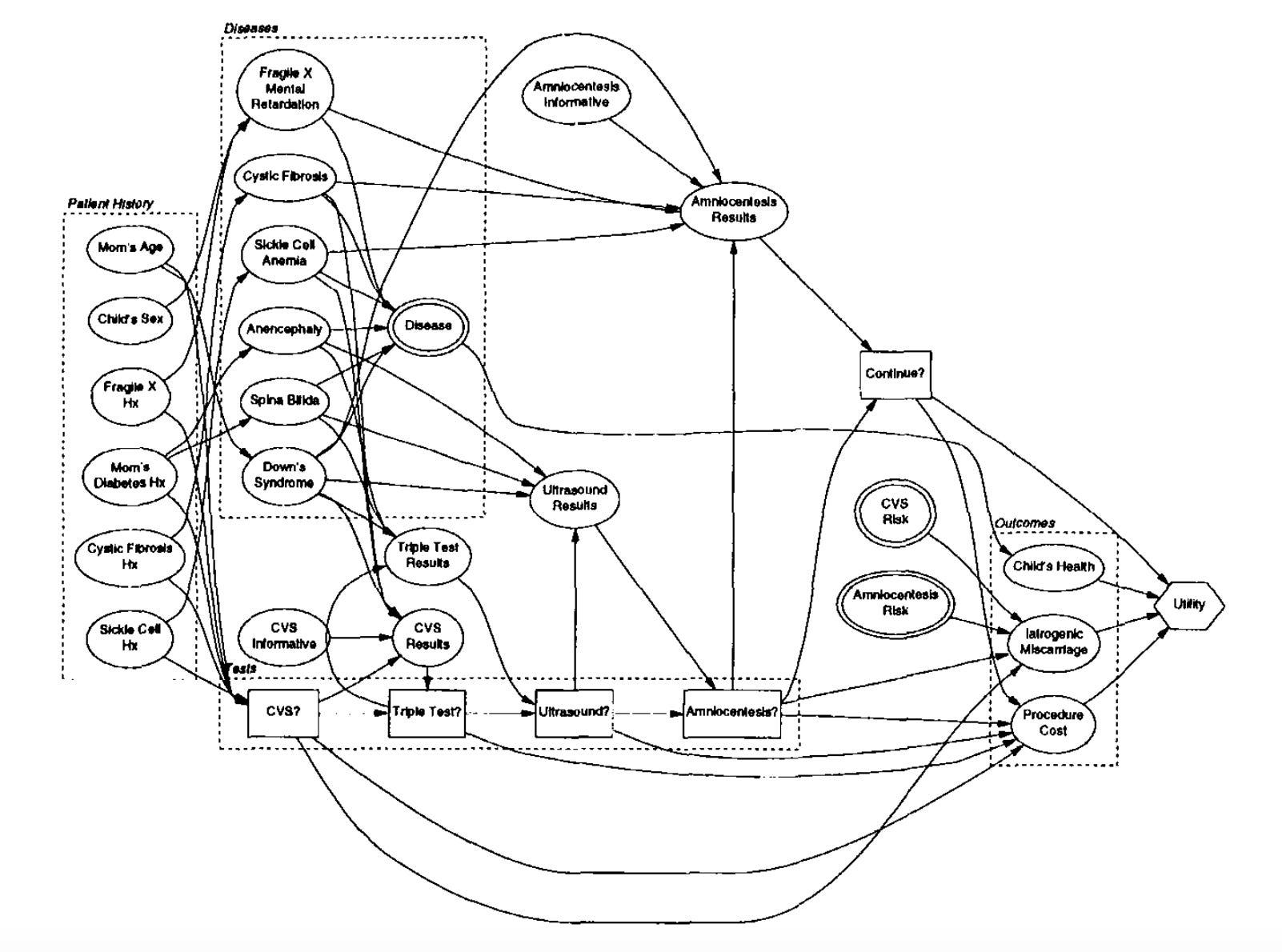
This very well-designed, thoughtful, and intellectually useful graphic seems unlikely to survive contact with myriad clinical realities.
It would be a huge advance in clinical medicine if doctors just gave patient true and false positive and negative outcome numbers and consequences like Harding Center fact boxes for pretty much any test they offer. Much less all that information on all these different possible tests in this sort of complex model. Much like probability elicitation as a science, it just doesn’t seem to be happening in the real world.
From an admittedly still fairly naive perspective, that seems to be the core (quantitative) decision analysis problem: It may or may not work, for some value of working. For instance, Yu et al’s 2021 meta-analysis found decision aids “could significantly improve knowledge and decision-making satisfaction, reduce decision conflict, increase the proportion of women who make informed choice and had no influence on anxiety and decision regret.” The authors concluded nurses should use DAs more, but it’s not clear women themselves would actually want that.
What do people want anyway?
Utility elicitation and a brief glimpse of the abysss
Asking people how much they think something happens (probability elicitation) may seem different from asking them why they care about different stuff that can happen (utility elicitation), but the two are deeply intertwined. Keeney & Raiffa’s Decisions with Multiple Objectives: Preferences and Value Tradeoffs (1976) is the foundational text on multi-criteria decision analysis and trade-offs. Who are these people? Step into my rabbit hole…
Howard Raiffa, a Bayesian decision theorist who co-wrote the book on decision analysis in the value conflict context (see above), is also known for giving Navy scientist John Craven the idea for Bayesian search theory. This offers an alternate way to apply Bayes’ rule in the context of mass screenings for low-prevalence problems (“the dangerous structure”) from the one I’ve been mulling following Fienberg. Instead of searching the haystack for needles and sorting it once (applying the test), it seems you keep sorting the piles (tuning your parameter optimization, making the classification better in the process).
Doubtless this description is a vast oversimplification (please email me with suggested readings/sources for the necessary deeper dive). One of the things I need to thoughtfully consider that may have been answered, or may be an open empirical question, is whether or to what extent Bayesian search represents a competing paradigm, or a missing element of how mass screening really works in reality. Possibly this is a more technical than conceptual point: “Bayesian search” could be a term of art (especially in AI/ML), while people could be updating their priors in real life in ways that make mass screenings work better than expected if we’re just wary about the base rate bias… It’s still important to get the terms right, but what we’re really interested in is how these things affect people.
What if mass screenings for low-prevalence problems tend to work better than expected, because people update priors dynamically in real life instead of just applying a one-off test? In some cases, this is more plausible than others. In the world of cancer screenings, for example, doing a yearly PSA blood test just to see if/when it suddenly spikes and then think about what you want to do with that information with knowledge of when it happened, given your then-current health status and age, might make sense even though, in the world of the Harding Center fact box, the one-off test looks pretty clearly irrational (and leading experts tend to agree). By contrast, mammography arguably doesn’t make net sense as a one-off or as an annual test, in part because the test and its repeats all risk iatrogenesis (e.g., from radiation exposure). Similarly, some security case studies have better claims to looking more like parameter optimization than others.
We need to know when mass screenings are actually Bayesian searches in disguise (e.g., when you know how people use them on the ground), how some of them might be repurposed that way to minimize harm and maximize benefit (e.g., when patients know enough to do this), and why this is sometimes the right or wrong line of questioning (i.e., what structural conditions make this move more or less plausible). Maybe mass screenings for low-prevalence problems aren’t a dangerous structure. Maybe they’re just tools you can use wisely or unwisely, like anything else.
Bottom line, this sort of move prospectively shifts the question from “what’s the balance of the accuracy-error trade-off?” in a one-off test context, to “how do we best update our priors given new information?” in a search.
What if this is what the sort of decision analysis tool Yu et al’s studies dealt with do? What if it’s what PANDA does? What if it’s what many mass screenings for low-prevalence problems already do in practice? Would this mean that the Stephen Fienberg/Harding Center-flavor table of frequency-format true/false negative/positive outcomes is a model that is both useful and wrong?
That’s how we should already think of models, of course. But I like this particular model so much!
The trick here is changing the structure of the problem from one focused on the accuracy-error trade-off at the population level, to one focused on finding the needle. That’s also essentially what AI/ML that seems to break the mathematical law does when it holds one form of error constant. It’s not something society has agreed to do, because at least in theory, we care about assessing net costs and benefits according to accepted scientific evidentiary standards.
But this is not how the real world already works. It would be a huge reform success to make it so, in pretty much any policy context whatsoever.
To tune the picture darker, some people argue we already have mass surveillance of various forms in the security context. Technopolitical safeties on its extent and abuse are the historical exceptions to the modern Western rule.
So if:
society already has pervasive mass screenings for low-prevalence problems,
they work better than the simple story about the accuracy-error trade-off backfire, because:
for one thing, they typically involve applying Bayes’ rule repeatedly instead of once, as when doctors do another sort with additional testing, or security forces do another sort with another source of data — or many (but it’s hard to know exactly how this works in many settings due to nontransparency), and
for another, they might invoke deterrence in strategic interactions, but it’s hard to model, and
we’re not about to agree to do net cost-benefits analyses before implementing these or any other sorts of policies, anyway…
… then what exactly is the point of shouting about Bayes’ rule from the hilltop just because we know something about the base rate bias and how to correct it?
You might think the point is to make the world a better place through science. That’s what I like to think. But what if that’s (also/instead) motivated reasoning? One of Raiffa’s best-known critics was Daniel Ellsberg, Pentagon Papers whistleblower and decision theorist whose paradox suggests people tend to prefer choices with risks they can quantify over those with unknown risks. This is consistent with other literature on cognitive bias suggesting probability framings shape risk perception in irrational ways.
Ambiguity/uncertainty-averse researchers could think it’s helpful to people to quantify risks, because we’re ambiguity/uncertainty-averse like everybody else. But in quantifying risks, we could actually make uncertain risks seem more certain than they actually are. And change people’s preferences to be more tolerant of those risks by misrepresenting them as relatively quantifiable and certain.
In other words, maybe critiquing mass screenings for low-prevalence problems by quantifying the hypothetical accuracy-error trade-off risks backfiring. As a simplifying heuristic, it misrepresents uncertain risks as certain, which could increase people’s tolerance of them — while also de-emphasizing how many planes of uncertainty about their risks remain and what that means.

Getting back to probability elicitation, getting experts to quantify uncertain risks could similarly backfire on researchers trying to make estimates more accurate if it misrepresents uncertainty as certainty instead of actually reducing it. I would like to see validation establishing that these methods don’t do that before trying them on the road. I don’t see the evidence. I want to do a good job getting experts to talk about uncertainty when they give me information. But I’m not sure we really know how to do that as a matter of scientific method.
So maybe it’s a good thing that probability elicitation is underused, and utility elicitation (from what I can tell) is even more of a methodological orphan.
The bright side
This looks like a great research area for some enterprising young methodologist who likes talking to experts. In theory, the audience is quite large, the need is huge, and the evidence base should be easy to improve. We need probability elicitation tools that include utility elicitation and that account for uncertainty aversion, base rate bias and other common distortions — without accidentally reinforcing them.