
Can AI Break the (Mathematical) Law?
Examining two recent claims of exiting the accuracy-error trade-off with machine learning

Some things are inescapable — like death, taxes, and the universal mathematical laws that govern our world. Yet, recent research claims to escape the inescapable — to exit the accuracy-error trade-off with artificial intelligence and machine learning (AI/ML). Are these breakthroughs, or illusions?
At the heart of the trade-off in question lies a simple but stubborn reality: most cues in the world are probabilistic. This isn’t a failure of science or technology. It’s the structure of reality itself.
And it implies that, when we attempt mass screenings or interventions for low-prevalence problems, we will generate overwhelming false positives — mistakenly flagged cases that (being common) overwhelm the true positives — correctly identified cases (the rare). Along with other consequences of these programs — false negatives, reverse causality, and resource allocation shifts — these false positives threaten societal harm when sorting the needles (true positives) from the haystacks (false positives) leaves persistent uncertainty and carries costs.
This is a consequence of the accuracy-error trade-off implied by the maxim of statistics known as Bayes’ rule. We can minimize false positives, but at the expense of increasing false negatives; or we can minimize false negatives, but at the expense of increasing false positives. Thus, these programs offer what Fienberg writing for the National Academy of Sciences on polygraphs called an unacceptable choice between too many false positives in one possible mode, and too many false negatives in another.
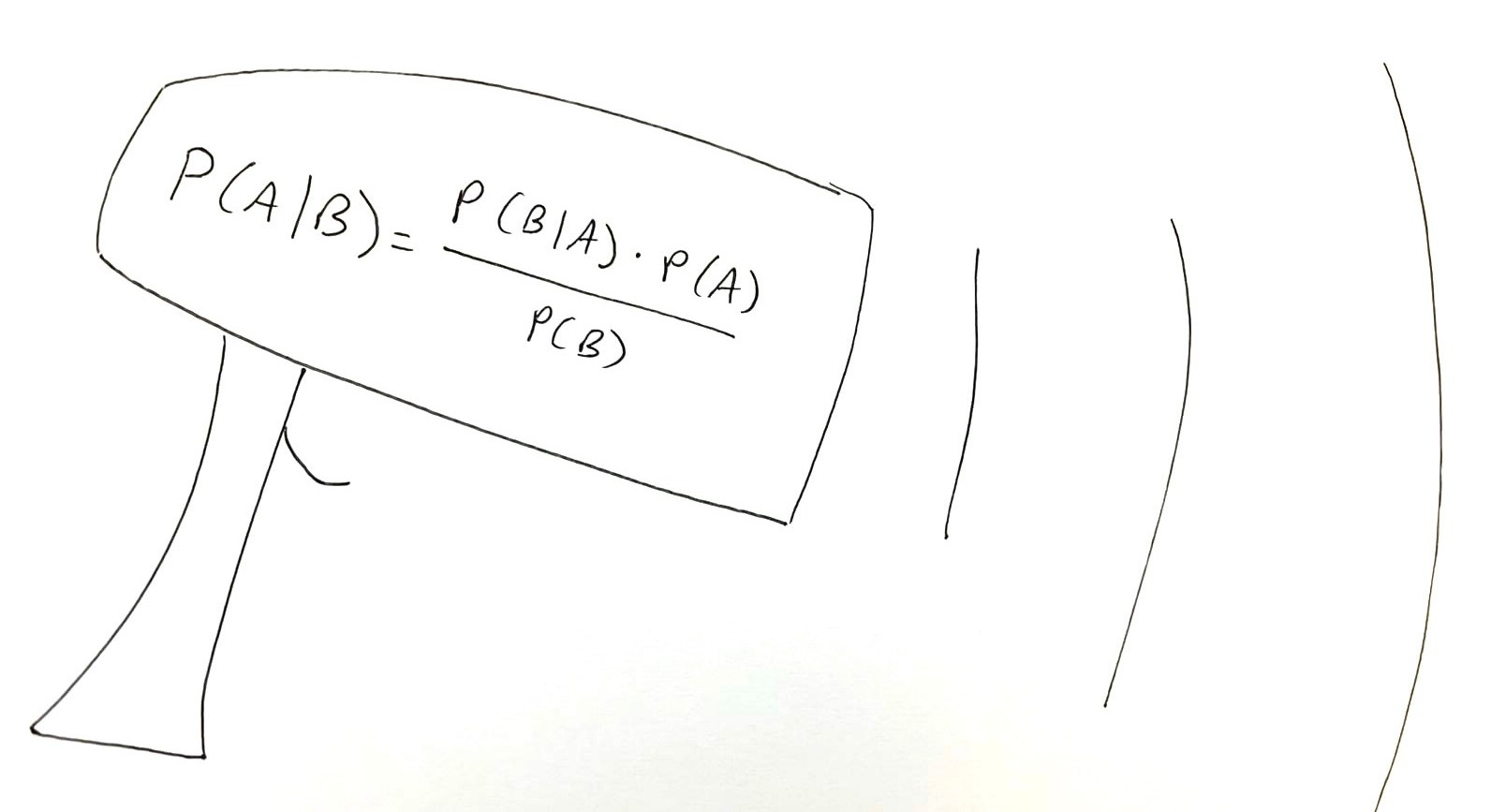
Bayes’ rule codifies this accuracy-error trade-off, implying that mass screenings or interventions are doomed to fail under conditions of rarity, uncertainty, and secondary screening harms. Examples of such programs include: polygraphs, iBorderCtrl and other next-generation “lie detectors,” Chat Control, Lavender + Gospel, Star Wars, etc. in security; mammography for breast cancer, PSA testing for prostate cancer, and many other tests and interventions in medicine; AI screening of student papers for plagiarism or AI use in education; trust marker screening for quality heuristics in scientific publishing; and mass screening for misinformation on social media/digital communication platforms. As digitalization and other technological advances make it easier to conduct these sorts of screenings or interventions, programs that share this potentially dangerous structure multiply, along with their invisible risks to society.
At least, that’s a standard statisticians’ argument about why techno-solutionism is misguided — and many programs that share an identical mathematical structure (i.e., signal detection problems) threaten massive societal damages to precisely the interests and people they claim to advance and protect.

Practitioners and optimists à la Katie Goodman (“It’s All Gonna Be Okay!”) tend to disagree — arguing that we can beat these constraints. “You can’t escape math,” say the mathematicians. To which some say…

Let’s look at two recent case studies in health where researchers appear to claim they escaped the accuracy-error trade-off with AI/ML. In antibiotic prescribing for urinary tract infections (UTIs) and imaging for early breast cancer detection, researchers claim to use better tech to beat these constraints…
Case 1: UTIs in Danish primary care (Ribers & Ullrich)
Michael Ribers and Hannes Ullrich recently demonstrated that AI-assisted prescribing for UTIs in Danish primary care hypothetically reduced overprescribing by about 15-20% (95% CI 15.1-20.8%) (see also my previous thinking on this research in this post and this talk). The simulated reduction in false positives did not come at the expense of more false negatives — a result they achieved by fixing the false negative rate as constant in their counterfactual.
This seems to break the law. The mathematical law. Bayes’ theorem. The implications of which in this context include the accuracy-error trade-off. What, who, where, when, why, how?
The explanation (Ullrich clarified by email) comes on p. 456-457, the first paragraph in Section 5.2, Eq. 2, and Appendix E. To wit:
We aim to evaluate policies motivated by the broad public health objective of reducing antibiotic use. However, the policymaker’s preferred outcome depends on α and β which are, in general, unknown. To make progress, we adopt an approach inspired by Kleinberg et al. (2018a) and focus on counterfactual prescribing that keeps the number of treated bacterial infections unchanged and minimizes overall antibiotic use.Footnote12 Observing Eq. 2, this approach guarantees an increase in payoffs for any α and β.
(Footnote 12 specifies: “This specific policy objective also minimizes overprescribing since the change in prescribing to non-UTI cases can be written generally as ∑i∈Iδi(1−yi)−∑i∈Idi(1−yi)=∑i∈I(δi−di)−∑i∈Iyi(δi−di), which equals the change in antibiotic use when the change in treated UTI, the last term above, is zero.”)
So what does it mean that Ribers & Ullrich model Kleinberg et al’s approach?
More on Kleinberg et al
Kleinberg et al deserves a more in-depth look in a future post (NBER Working Paper 23180, aka “Human Decisions and Machine Predictions,” Jon Kleinberg, Himabindu Lakkaraju, Jure Leskovec, Jens Ludwig, and Sendhil Mullainathan, 2018. The Quarterly Journal of Economics, Vol. 133, No. 1, p. 237-293). Briefly, they used ML to improve New York bail decisions such that they could either reduce false negatives (decreasing post-release crime by 24.7%, matching judges’ current release rate) or reduce false positives (reducing jail detention from 26.4% to 15.4%, a 42% reduction; p. 27 NBER version).
Substantively, Ribers & Ullrich chose the superior case study; Kleinberg et al look at bail vs. detention decisions, arguing they “overcome” the counterfactual prediction problem (what would have happened, had judges freed jailed defendants) (p. 4). They do this in an elegant empirical way, partitioning their data several times and testing their algorithm on parts of the dataset they didn’t already use (p. 15). Still, R&U don’t have to make this kind of argument, because the Danish UTI data actually let us observe physicians in the ROC space. The validation problem isn’t arguably/theoretically solved in their case study; it’s solved. Conversely, because we don’t know what defendants who were jailed would have done had they been released instead, and no amount of data partitioning can tell us, the validation problem persists in Kleinberg et al’s case study.
Methodologically, Kleinberg et al clarify why it may look like AI/ML breaks the (mathematical) law by reducing false positives while holding false negatives constant or vice-versa. But what’s really going on is that computers are (sometimes) beating human experts at solving signal detection problems, with humans more distracted by noise and AI being trained to hone in on more signal (p. 37). In particular, humans (here, judges) tend to underweight key factors like previous criminal record (p. 41). By contrast, this is exactly the kind of data ML uses to optimize practical outcomes. Similarly, Kleinberg et al suggest that unobserved variables like internal states may contribute to misprediction (p. 7). Error and bias: the human decision-making story.
In other words, just because we live in a universe of mostly probabilistic cues and are stuck with that structure of the world, doesn’t mean we can’t do a better job using technology to correctly classify according to those cues. Of course, not all tech is created equal for this purpose. Kleinberg et al note that judges in NYC (where their dataset is from) already have access to a pre-trial release risk assessment decision aid tool. But it’s not that accurate, so judges seem to not use it that much (p. 39). There’s another example of human-AI complementarity: humans aren’t perfect, but maybe we know when AI isn’t that good, either.
Point being, AI/ML can beat humans at picking out signal from noise. It does that within the implications of universal mathematical laws including the constraints of the implications of Bayes’ rule. In so doing, it can look like it’s breaking the law by exiting the accuracy-error trade-off that Fienberg and others have long warned we can’t exit. There’s an acknowledged black-box element to this (p. 13).
Back to Ribers & Ullrich
Ribers & Ullrich’s results come from a simulation. But one can envision an experiment testing whether this works in practice. It could seek to answer open empirical questions about how people will actually use the tech in practice, such as:
Do doctors appropriately delegate hard and easy cases, but not intermediate-level ones, to the AI? And does their accuracy in those mezzo cases stay the same?
Does automation bias lead some doctors to take the AI’s decisions at face value? What about its opposite — do some doctors just ignore the AI’s recommendations across the board?
What about equilibrium effects? Do strategic actors try to game the system by exploiting thresholds?
While these questions remain unanswered, this case study offers a rare opportunity to resolve the validation problem.
But it seems to me that the authors may be stuck in a (solveable) validation problem loop, nonetheless: ML could work in one sample, results could not generalize well to other samples (a typical AI/ML problem), accuracy could accordingly tank in a more heterogeneous population — and then ML could work again to improve outcomes once we know the right answers in those samples.
In which case, you can work backwards to improve accuracy as long as your population doesn’t change. But you know your population changed and it mattered only because you can always go back and check your answers. This is not a universal feature. And it’s my favorite thing about this case study…
It sits on a pole of the continuum of grappling with the validation problem. It’s a very special (beautiful) case study, because here the problem is solveable. Ribers and Ullrich’s human-AI complementarity works (in theory), because we gain new information from that real-world resolution of the validation problem: we get to observe doctors in the ROC space (false positives plotted against true positives) because of the three-day delay between their prescribing decisions and the “gold standard” lab test results determining whether patients really had UTIs, or not.
In lie detection, by contrast, the problem may be unsolvable: it may not be possible to devise an experiment in the real world that would enable us to scientifically validate the test. You might think validation is uncharacteristically tough in security — where dedicated attackers have incentives to game the system — but possible pretty much everywhere else. In reality, though, it’s an intractable problem across diverse issue areas.
Even in the context of cancer — where you might think the adversary is inert, biological, and its presence or absence dichotomous and knowable — validation is still a persistent problem. As mammography critics point out, we still struggle to validate breast cancer screening tests among many others. The best available data don’t establish the screening yields all-cause mortality gains in exchange for a lot more diagnosis/intervention. One of the reasons is that many identified cancers don’t progress (e.g., most ductal carcinoma in situ or DCIS cases in the breast cancer context). And we don’t know which identified cases were going to matter clinically or not. We don’t necessarily know which cases were false versus true positives. So we never get to observe radiologists or other physicians operating in the ROC space like we do in the UTI case study, because there is no answer sheet coming three days later to go back and check their work.
But surely there are more examples like this one where we can solve the validation problem…
Toward another case study: what about infant feeding?
Being somewhat obsessed with infant feeding, I wonder if there might be an analogous, validation-friendly setup in this case study? Imagine testing neonates (via blood draws, unfortunately) as the analogue of UTI lab tests, and formula-feeding recommendations as the analogue of prescribing antibiotics. The outcomes are:
False positives: Doctors advise formula-feeding (e.g., on the basis of neonatal weight loss), but bloodwork later shows no evidence of jaundice, hypoglycemia, or hypernatremia.
False negatives: Doctors advise continuing breastfeeding, but bloodwork later reveals underfeeding complications.
A dataset like this could allow us to observe clinicians’ decisions in the ROC space and refine heuristics for reducing false negatives while holding false positives constant — reducing neonatal readmissions. Whether such data actually exists, I don’t know (and I hope blood draws for neonates aren’t that common).
On the plus side, this could prevent a lot of neonatal readmissions and possibly long-term harms. But critics might charge that evidence of underfeeding complications doesn’t establish harm. We don’t know what “safe” thresholds are for neonatal jaundice, hypoglycemia, or hypernatremia. So this kind of approach could cause a lot of overtreatment. If you believe “Breast is Best,” that would likely be unacceptable to you.
This sort of interpretive bind isn’t sui generis. AI/ML don’t magically resolve the disagreements wherein well-informed stakeholders may prioritize different goals or values. In infant feeding, I would argue for prioritizing harm prevention — avoiding underfeeding complications. Others prefer to maximize breastfeeding rates, even at the cost of increasing underfeeding complications, neonatal rehospitalizations, and possibly long-term harm.
These preferences are shaped by myriad factors including personal experiences (e.g., I want to protect other children from going hungry like my son did), sociopolitical dynamics (e.g., people can view their positions as feminist on both sides), financial incentives (e.g., career breastfeeding proponents have incentives to not torpedo their careers), and bias (e.g., knowing there’s a huge literature on how great breastfeeding is without knowing that it fails to account for causality). No algorithm can get us out of this web of being embedded social and political animals prone to making mistakes and not fully comprehending the limitations of our own perspectives.
AI/ML are tools like any other. They reflect human expertise, not magic. They’re only as good as the human decisions they’re designed to complement. And those human decisions are constrained by universal mathematical laws.
So what’s going on in Ribers and Ullrich? Is this for real?
How does this work?
The AI here reflects another form of human expertise in play. It’s not magic — it’s researchers using technology to study the data and improve outcomes in line with their chosen aims. In this case, they prioritized reducing antibiotic overprescribing (false positives). They could just as easily have focused on reducing false negatives, which might matter more to patients and which also contribute to antibiotic resistance — the bigger-picture thing they want to reduce: “When physicians treat instantly and bacteria are found, these have one to five percentage points lower resistance levels than when physicians decide to wait and bacteria are found.”
By observing physicians in the ROC space (false positives vs. true positives), the model assessed when it was better for the AI versus physicians to decide whether to prescribe antibiotics for UTIs. Rather than escaping the accuracy-error trade-off, this approach shifts decision modes based on case type (easy and hard for the AI, mezzo for the docs). It’s as if the different difficulty-level cases are being given different interventions instead of the same one. This approach could hit a snag in practice (as AI/ML often does) if applied to clinical situations more diverse than the ones it was trained on.
There’s also an acknowledged black-box element to what’s going on here: We still don’t know why this works. Are there cognitive or psychosocial biases in play (that doctors might learn to correct for), that make them worse than AI at diagnosing the easy and hard cases? For instance, the AI dramatically reduced overprescribing to immigrants. Could this reflect a dominant Danish social desirability or xenophobia-avoidance bias?
More generally, could explicit training on how to best use relevant heuristics like gender and age help doctors decide easy/hard cases as accurately as the AI? Were common cognitive biases such as anchoring bias in play, where doctors think they should prescribe a certain amount of antibiotics to a certain number of patients, perhaps by subgroup? Will doctors then adjust their behavior if they know they’re only seeing certain cases?
Because we don’t know the mechanisms of the apparent accuracy gains, we can’t predict whether the theoretical constraint of holding the false negative rate constant in the model produced results that will replicate in practice. So it’s we might still say this case represents an instance of the (typical) disagreement between statisticians and practitioners about whether the accuracy-error trade-off is indeed inescapable, or not. Lack of real-world efficacy data on the human-AI complementarity modeled here leaves this an intriguing, hypothetical case study for now.
Meanwhile, there’s a growing body of research on another case with more real-world efficacy data: Breast cancer screening is one of the (if not the) best-studied medical interventions ever, with a great many recents efforts to improve it using AI/ML. Some of these efforts have already taken AI/ML lab results to the field — but, unlike in the UTI case, the validation problem persists…
Case 2: Imaging screenings for early breast cancer detection (Shen et al, Lauritzen et al, Pedemonte et al, etc.)
In recent years, several teams have tried reducing false positive breast cancer screenings without increasing (and perhaps also reducing) false negatives. The future probably lies in ultrasound for this purpose, because it works better for more women. But it doesn’t detect microcalcifications, a possible early cancer flag. And adding ultrasound with its current accuracy to existing standard mammogram screening increases already substantial false positives for very small cancer identification gains. So there is no reason to change the status quo yet. For now, mammograms remain the standard.
Mammograms have problems. They don’t image mammographically dense breast tissue — as well as they do relatively fatty tissue. This characteristic has to do with the relative amounts of glandular, fibrous connective, and fatty breast tissue, and supposedly isn’t something you can feel or see yourself (though higher BMI and having kids correlate with less dense breasts). This is problematic, because breast density correlates with increased breast cancer risk.
Also, the equipment is heavier, more expensive, and harder to operate safely and maintain — making it less accessible globally than the alternative, ultrasound (especially in resource-constrained settings).
Mammography also risks possible iatrogenesis from radiation exposure and compression — risks ultrasound does not carry.
Worst of all, despite being one of (if not the) most researched medical interventions ever, mammography doesn’t offer an established all-cause mortality benefit. Everyone should be able to look at a top-level risk literacy representation of the available evidence — i.e., the Harding Center fact box — and decide for herself. But it’s a reasonable choice to not have one at any age.
So let’s start with the future…
Ultrasound screening: Shen et al
Shen et al 2021, a team of U.S.-based researchers, conducted a retrospective reader study using the NYU Breast Ultrasound Dataset including 288,767 breast ultrasound exams consisting of almost 5.5 million images from 20 affiliated imaging sites and cross-validated with the Breast Ultrasound Images from the Cairo, Egypt Hospital for Early Detection and Treatment of Women’s Cancer consisting of 780 images from 600 patients (“Artificial intelligence system reduces false-positive findings in the interpretation of breast ultrasound exams,” Yiqiu Shen, Farah E. Shamout, Jamie R. Oliver, Jan Witowski, Kawshik Kannan, Jungkyu Park, Nan Wu, Connor Huddleston, Stacey Wolfson, Alexandra Millet, Robin Ehrenpreis, Divya Awal, Cathy Tyma, Naziya Samreen, Yiming Gao, Chloe Chhor, Stacey Gandhi, Cindy Lee, Sheila Kumari-Subaiya, Cindy Leonard, Reyhan Mohammed, Christopher Moczulski, Jaime Altabet, James Babb, Alana Lewin, Beatriu Reig, Linda Moy, Laura Heacock & Krzysztof J. Geras, Nature Communications, Vol. 12, No. 5645 (2021)).
As with mammography and other mass screenings for low-prevalence problems, false positives overwhelmed true positives in the dataset, with 26,843/28,914 biopsied exams yielding benign results (p. 2). We want to see their findings in the same frequency-format terms for improving Bayesian statistical intuitions — to get a better sense of net benefits and harms — but they’re not presented that way.
They found using the AI helped radiologists decrease their false positives, reducing requested biopsies 27.8%, without raising false negatives (p. 1). Like Ribers & Ullrich, they emphasized the potential power of complementarity to improve outcomes. In particular, they found, in a cancer-enriched reader study using ten radiologists, that “hybrid models reduced the average radiologist’s false positive rate” from 19.3% to 12% and while increasing the average radiologist’s PPV — meaning more hits of cancer per biopsy; p. 9. “Overall, hybrid models were able to reduce the number of FP [false positive biopsies] while yielding the same number of fewer FN [false negative diagnoses] than the respective readers” (Supplemental Table 7, Supplement p. 7).
Shen et al made a typical mistake in the breast cancer screening and similar literatures of assuming the validation problem is solved when it is not. E.g., they say biopsy or surgical excision definitively determines whether a patient has cancer (p. 5). But, in reality, experts can disagree about whether patients with DCIS on biopsy have cancer, or not. This ambiguity may have distorted their results. For instance, their true positive calculations may actually contain increases in probable false positives if DCIS is considered.
In addition to claiming that using AI to aid their decisions improved radiologists’ accuracy and error, Shen et al reported finding that AI could assist radiologists in triaging ultrasound exams by automatically dismissing the easy cases (most low-risk benign exams) and escalating the hard ones (high-risk cases) “to an enhanced risk assessment stream” (p. 9). This seems almost analogous to Ribers & Ullrich’s finding the AI decided the easy and hard cases better than physicians, except that here the hard cases are triaged for further human expert evaluation instead of being decided by the AI.
One of the main limitations of this study is that they didn’t try it on the ground like Lauritzen et al (Denmark) and Lång et al (Sweden) did…
Mammography with AI: Lauritzen et al, etc.
Danish machine learning researchers led by Andreas Lauritzen, a machine learning postdoc at the University of Copenhagen, have been spearheading the use of AI to similarly improve mammography payoffs. Their basic claims and findings are structurally identical to Ribers & Ullrich’s:
That human-AI complementary decisionmaking permits decreasing false positive rates without increasing false negative rates, changing the outcome spread to more credibly favor net gains than previous evidence suggested. E.g., reporting screening incorporating AI had comparable sensitivity and higher specificity than radiologists alone (p. 42, 2022).
This complementarity involves automating the easy and hard decisions, and giving experts the intermediate-difficulty level ones. E.g., in their first main retrospective simulation study, they excluded mammograms scored <5 from further scrutiny, sent mammograms with a score greater than the recall threshold straight to recall (recalling the woman), and sent intermediately scored mammograms to two radiologists (p. 44, 2022).
They did this in two moves, by (1) holding false negatives constant... This involved assuming interval cancers were false negatives, and setting the number of screen-detected cancers missed by AI to equal the number of suspicious screening exams later diagnosed as interval cancer (p. 44, 2022).
… And then (2) using complementarity to reduce false positives. This learning wasn’t immediate. E.g., in their first retrospective simulation study, simulating AI-only screening increased false positives substantially — up 5,825/2107 (276.5%) — in comparison with pure radiologist readings (2022, p. 45). Then, when they let the AI and radiologists play together — automating away the easy and hard cases from the radiologists’ workloads — the complementary AI-radiologist screening may have reduced false positives substantially (down 529/2107, or 25.1%), along with reducing radiologists’ workload substantially (by 71,585/114,421, or 62.6%; 2022, p. 46).
The typical worry with these sorts of AI results is that accuracy tanks when you go from lab to field, because the real world is more heterogeneous than the training dataset. Lauritzen et al (and basically everyone else) acknowledge this.
More on Lauritzen et al 2022
“An Artificial Intelligence-based Mammography Screening Protocol for Breast Cancer: Outcome and Radiologist Workload,” Andreas D. Lauritzen, Alejandro Rodríguez-Ruiz, My Catarina von Euler-Chelpin, Elsebeth Lynge, Ilse Vejborg, Mads Nielsen, Nico Karssemeijer, and Martin Lillholm, Radiology, July 2022;304(1):41-49.
Provides helpful historical and scientific context:
AI-assisted mammography screening has been around for a long time, but initially increased false positives for no benefit in reducing false negatives (Fenton et al 2007). Like other AI, it was bad, but it got better…
Similar recent studies have found similar results using other samples and other AI vendors in other country contexts.
Rodriguez-Ruiz et al 2019 found a mammogram reading AI’s AUC was similar to that of radiologists’ average, and radiologists’ sensitivity and specificity may have both improved slightly with AI support.
McKinney et al 2020 found AI was more accurate than any participating radiologist, reducing false positives and false negatives by single digits in US and UK samples.
Salim et al 2020 hit on complementarity between radiologists and the best of three tested AIs for reducing false negatives in a Swedish sample.
Kim et al 2020 reported AI had a better AUC compared to radiologists in South Korean, UK, and US datasets. In a reader study from two institutions, it improved radiologists’ performance — decreasing both false negatives and false positives (see Table 3).
Pacilè et al 2020 found AI use decreased radiologists’ false negatives on average, and may have decreased their false positives.
Lång et al 2021 found AI could reduce false positives without increasing false negatives by scoring the sample for cancer risk 1-10 and excluding mammograms scored 1 and 2 from radiologist reading.
In contrast, Rodriguez-Ruiz et al 2019 found using a risk scoring 1-9 that using 2 as a threshold reduced radiologist workload (which implies reducing false positives) while only increasing false negatives a little bit (“excluding 1% of true-positive exams”).
In a retrospective simulation study, Dembrower et al 2020 found letting AI triage mammograms into no radiologist, regular radiologist assessment, or enhanced assessment categories could substantially reduce false negatives. They didn’t explicitly say it could also substantially reduce false positives, but this would seem to be a logical implication of their finding that it could substantially reduce radiologist workload (because no radiologist reading implies no call-back for a false positive).
Possible signs of analytical trouble:
A reference to increase in breast cancer incidence (p. 41) without noting decreasing mortality rates, and the debate over what both mean. Is incidence increasing because of more detection or a higher base rate? Are mortality rates falling because of better treatments or because overdiagnosis means more cancers get detected that mostly would not kill women (e.g., DCIS)? There’s some evidence favoring the overdiagnosis story here (a topic for a different post).
The analytical structure reflects the same focus on breast cancer cases, not deaths, as the outcome of interest. See, e.g., Tables 1-3, where the column headings are: Sample, Screen-detected Cancer, Interval Cancer, Long-term Cancer, and No Cancer. This structure implicitly assumes the validation problem is solved, but it’s not — we need to know (arguably) about deaths, and specifically which death(s) (if any) were prevented by the screening, diagnosis, and treatment train. Persistent uncertainty remains about this on a case-by-case basis. At the very least, we want to know whether there’s an aggregate all-cause mortality benefit. If we don’t know that (still), we should get a quantified breast cancer mortality benefit. This is absent.
This relates to a risk literacy issue common in medical and scientific research (i.e., not telling people what the research means in practical terms). Despite persistent uncertainty about which (if any) life was saved here, it would still be nice to have the estimate in terms of quantifying net benefits and costs that people care about. For this purpose, the Harding Center fact box remains the gold standard: we want frequency-format counts of false positive harms along with true positive benefits for improved Bayesian statistical intuitions, and get neither here.
The primary outcome of interest changes from improving screening accuracy/error (p. 41), to decreasing radiologist workload (p. 47). This is not just this team in this paper, but many others. The problem is that, in the real world, we arguably really want to reduce all-cause mortality to swing the net benefit-cost balance of these screenings (and others that share the same mathematical structure) by improving breast cancer screening accuracy and error rates. So we should be asking AI/ML to help us do that, not talking about accuracy/error rates while asking it to decrease the radiologist workload. Both are distractions from the actual outcome of interest.
Radiologist workload is a resource allocation problem. Meanwhile, these programs’ on whether they yield a net benefit in the first place. In other words, the greater efficiency gain is to cut the program (reducing radiologist workload 100%) with your AIs tight shut if it doesn’t pay off anyway. The problem with this is acceptability (people like their existing programs — patients and professionals alike).
It’s worth noting this is a difference between the UTIs case and the breast cancer screening case: The benefit to patients of treating UTIs with antibiotics is self-evident. But the net benefit to women of mass screening for breast cancer is unproven. In this way, mass preventive interventions for low-prevalence problems are structurally different from symptomatic or targeted investigations or interventions. The bar of proof has to be higher that they don’t incur net damages due to the implications of Bayes’ rule.
That’s not to say that efficiency concerns have no place in these analyses. To the contrary, they can implicate zero-sum resource allocation consequences of these programs. But these consequences should be quantified, not implied.
More on Lauritzen et al 2023
“Assessing Breast Cancer Risk by Combining AI for Lesion Detection and Mammographic Texture,” Andreas D. Lauritzen, My C. von Euler-Chelpin, Elsebeth Lynge, Ilse Vejborg, Mads Nielsen, Nico Karssemeijer, and Martin Lillholm, Radiology, 2023; 308(2):e230227. An AI scored Danish screening cohort mammograms using the typical 0-10 risk scoring with a new type of model combining short-term risk stratification based on lesion detection and long-term risk stratification based on texture and percentage mammography density. It improved AUC for interval and long-term cancers better than either type of model alone. These are false negative reductions.
More on Lauritzen et al 2024
“Early Indicators of the Impact of Using AI in Mammography Screening for Breast Cancer,” Andreas D. Lauritzen, Martin Lillholm, Elsebeth Lynge, Mads Nielsen, Nico Karssemeijer, Ilse Vejborg, Radiology, June 2024;311(3):e232479. In a retrospective study of Danish mammography screenings before and after AI system implementation, the authors found using AI substantially reduced radiologist workload, decreased false positives, and decreased false negatives.
A recurrent sign of possible analytical trouble: The authors mention “All cancers in this study were screen-detected invasive cancers or ductal carcinoma in situ [DCIS] confirmed with needle biopsy following recall, a surgical specimen, or both” (p. 2). This implicates the problem of overdiagnosis, highlighting again that the validation problem here was not actually solved.
Some experts say most cases of DCIS don’t progress, so recalls and interventions like biopsy and surgery resulting from them pose serious risks including infection and disfigurement without offering proven benefits. The big-picture issue here again is that if mammography screening doesn’t offer a proven net benefit (no established all-cause mortality reduction despite a huge amount of research), then it’s not clear why we want to improve it instead of stopping it and trying something different.
Sure, that would be politically difficult because people like their programs. But maybe it’s not ok to run expensive programs that hurt people and may not save lives just because it looks good. Maybe we need to be concerned about establishing net benefit and/or ruling out net harm, first.
This detail also casts doubt on Lauritzen et al’s claim of reducing false positives. If part of what the AI system may have done is increased DCIS diagnoses, counting that outcome as a decrease in false negatives reflects at best a contestable categorization.
Lauritzen et al acknowledged this problem in their Discussion section, writing:
In both studies [theirs and Lång et al 2023’s report of an RCT on AI-assisted mammography], diagnoses of ductal carcinoma in situ were more frequent with AI support (in our study: 15.1% [64 of 423] before AI vs 20.4% [98 of 480] with AI; P= .04), which might be a concern in terms of overdiagnosis. According to Danish and European guidelines, the percentage of diagnosed ductal carcinoma in situ out of all diagnosed breast cancers (invasive and in situ) should be 10%-20% (p. 8).
So Lauritzen et al may be a nothingburger, insofar as they don’t credibly claim to have reduced both false negatives and false positives, after all. Rather, it looks like all this literature still fails to demonstrate an all-cause mortality benefit while at best demonstrating an increase in the risk of harm from overdiagnosis. Its authors have incentives to not come out and say that.
This is not surprising. The UTI case study is pretty special in how well it solves the validation problem. There must be other cases where it’s possible to solve it this well. But I can’t think of any, and breast cancer is certainly not one.
In this way, the breast cancer screening case highlights the limits of what AI can achieve. Far from escaping universal constraints, these studies illustrate how AI must work within existing trade-offs. Success depends not on bucking these constraints, but on using AI strategically to mitigate harms — without overstating benefits or rendering invisible serious risks like overdiagnosis and its consequences.
Overall, this fits the statisticians’ story that AI can’t break the law. We’re stuck in this world of mostly probabilistic cues, forcing us into the accuracy-error trade-off. Improving one degrades the other.
That doesn’t mean AI/ML can’t improve mammography. It means it has to be used differently to try.
If Shen at al were the future of breast cancer screening modality because they looked at ultrasounds instead of mammograms, perhaps Pedemonte et al are the future of improving breast cancer screening with AI because they don’t try to break the law. Instead, they reason AI can be used to reduce false positive harms alone, and focus on doing that.
More on Pedemonte et al
“A Semiautonomous Deep Learning System to Reduce False Positives in Screening Mammography,” Stefano Pedemonte, Trevor Tsue, Brent Mombourquette, Yen Nhi Truong Vu, Thomas Matthews, Rodrigo Morales Hoil, Meet Shah, Nikita Ghare, Naomi Zingman-Daniels, Susan Holley, Catherine M Appleton, Jason Su, Richard L Wahl, Radiol Artif Intell, May 2024;6(3):e230033.
The authors take reducing false positives as their goal, recognizing the trade-off implicated: fewer false positives implies more false negatives. In line with this, they found the AI missed two cancers across three datasets (both in a U.K. dataset, none in two U.S. datasets) (p. 5). They argue this is better than what the U.S. Preventive Services Task Force (USPSTF) did in moving the recommended screening start age from 40 to 50 in 2009 (before moving it back this fall) — a move that reduced false positives much more, but also increased false negatives much more accordingly (p. 7).
There’s still a lot of spin in this paper (e.g., claiming mammograms reduce mortality when all-cause mortality reduction is unproven, and ignoring risks of infection and disfigurement in listing harms from overdiagnosis, p. 1). But at least the authors know the (mathematical) law and present their results in line with its implications.
Until they don’t, claiming in the Discussion section: “We observe that even when the absolute sensitivity is 97.0%, the relative sensitivity can remain at 100%, suggesting that no new cancers would be lost in this paradigm” (p. 8). It’s unclear why they think they can exit the accuracy-error trade-off in this section, even though their design didn’t anticipate that being possible, and their results as presented earlier showed they didn’t do it. (The trade-off was just a fairly reasonable one.)
Breast cancer screening and AI
Overall, this is a burgeoning subfield with results often suggesting improved accuracy and error alike with the addition of AI to expert reading of breast cancer screening images, mainly mammography. This is the best-developed literature I’ve seen on using AI to improve mass screenings for low-prevalence problems.
But no one working on improving breast cancer screening with AI (that I’ve seen) mentions that this is a dangerous structure. Namely, the net benefit-harm impact of these programs is contested, all-cause mortality benefits are unproven, and overdiagnosis risks serious harms including infection and disfigurement from the major medical interventions like mastectomy that can result.
Moreover, no one presents their results in terms of frequency-format outcome spreads comparing different policy universes, when ideally we want to see those spreads in the universe without AI, the universe with technology-mediated expert decision-making in screening (complementarity) — and the universe without these screenings. This may reflect perverse incentives for researchers to promote these screenings instead of presenting the available evidence in such a way that the reader might question their wisdom even with AI improvement.
Worst, few researchers working on how AI can improve mammography seem to understand themselves as working within universal mathematical laws. If there are genuine methodological advances in AI/ML that let us break these laws, I don’t understand them.
Insofar as they are black-box, no one does. Insofar as they involve using data better to minimize bias and error, they’re not particularly technology-moored. Human experts could presumably be trained to better use the heuristics that work for their purposes, and to not use the ones that don’t.
Conclusion
Nobody breaks the (mathematical) law. AI/ML may sometimes seem to violate the implications of Bayes’ rule by reducing false positives without increasing false negatives, or vice-versa. But really it’s just using data to find signal in noise better than us humans — and avoiding adding as much noise as we do with our normal biases and errors. In other words, by working within constraints and partitioning large datasets to avoid overfitting, AI/ML can help improve accuracy and error rates — advancing policy objectives from security to health and beyond.
But we still have to think about what we’re doing. Can we really solve the validation problem to test whether a particular screening or intervention works? Does the available evidence establish net benefit or harm from the screening/intervention — or is it so limited or interpretive that we don’t know if we want to be doing the program at all, even if we could be doing it better with AI/ML? What costs accrue to whom from expending finite resources improving programs of uncertain net effects?
In the first case study explored here, Ribers & Ullrich’s research on using AI to improve Danish UTI treatment sits on a pole of these spectrums. The validation problem is really solved, antibiotics treat these UTIs (policymakers just want to reduce overuse to avoid resistance), and AI-human complementarity in these antibiotic prescribing decisions should actually give physicians some time back to spend on other tasks (helping patients). Just because I can’t think of any other cases like this, doesn’t mean they don’t exist. But it seems this is a very special case.
Case study 2, using AI to improve breast cancer screenings, sits in a different place on all these spectrums: The validation problem persists in cancer screenings. Patients with false positives don’t necessarily know they’re false positives, and may instead wrongly believe the screening and follow-up intervention has saved their lives. It may not be provable in particular cases whether this is true or false; we just know many cancers (e.g., DCIS for women and prostate cancer for men) don’t progress to become clinically meaningful, so in the aggregate, there’s an overdiagnosis problem.
This connects with the question of net harm/benefit, where we have to be clear on the outcome we want to move in policy terms. Is it cancer cases in this second case study, or cancer deaths — or all-cause mortality? If it’s cancer deaths and/or all deaths, we need AI/ML attending to that outcome, and not primarily or only to cases. Improving breast cancer screening by reducing false positives or false negatives may still not generate established net benefits. And since these mass screenings take a lot of resources, we might want to assess what they’re taking those resources away from and how that affects related metrics like women’s longevity.
All the techno whizz-bangery in the world — focused on the wrong problem — is not going to improve population well-being. This gets back to the innate, invisible dangers of mass screenings and interventions for low-prevalence problems. False positives (the common) will still overwhelm true positives (the rare), even if AI/ML improves their hit rates one way or another. Conditions of rarity, uncertainty, and secondary screening harms will still doom many programs of this structure to backfire, hurting exactly the people and ends they’re intended to protect and advance.
The problem in these cases is not that the programs aren’t accurate enough. It’s that the structure of the world dooms them to net harm society. Better tech can’t change that structure. Even if it can sometimes do the (seeming) impossible by better finding signal in noise, reducing false positives or negatives while holding the other type of error constant.
tl;dr
Like my dissertation haiku summary said:
Technology seems
neutral and data-driven.
Its use is human.
The promise of AI/ML is not to use data to escape the structure of the world, but to work more wisely within it. The challenge is knowing when and how to use it — recognizing the implications of universal mathematical laws, aligning with clearly defined policy goals and values, and testing as we go to assess what costs and benefits really accrue to whom.