
Old Rarity
On the affect effect, the description-experience gap, and (eventually) redesigning Rarity Roulette after getting great feedback


It seemed like a good idea at the time to make an app that lets you see some of my favorite examples of mass screenings for low-prevalence problems (polygraphs, mammography, PSA testing, and a prenatal test for DiGeorge syndrome); rejigger the population size, base rate, accuracy, and detection threshold; and read plain-language results as well as table or frequency tree hypothetical estimated outcome spreads, as well as see cumulative outcomes over time. So that’s what my first app, Rarity Roulette, does.
Maybe it was not such a good idea, after all. After inconclusive pilot 1, tables to trees redesign, inconclusive pilot 2, more readings on what the point of all this might be, pilots reanalysis and LLM contamination problem reflection, and last week posting the security case studies working paper (now live on SSRN as a preprint) that is a prelude to the medical case studies working paper for which someone might someday get good data (e.g., on mammography and colonoscopy on one pole of the spectrum of validation problem solvability; vaccines and abortion on the other) to do net effects modeling on programs of this structure and/or make other interesting points — I really think this was not such a good idea, after all.
Because the point of my coolest research, if you ask me, is that it’s uncertain what the net effects of these programs are. We think we’re so smart, but we just don’t know what we’re doing with these complex interventions on complex problems in complex societies. Meanwhile, my app itself only shows the classification pathway effects, ignoring the strategy, information, and resource reallocation pathways completely. The whole point of my causal modeling on programs of this structure is that this doesn’t give us net effects, which are what we should care about.
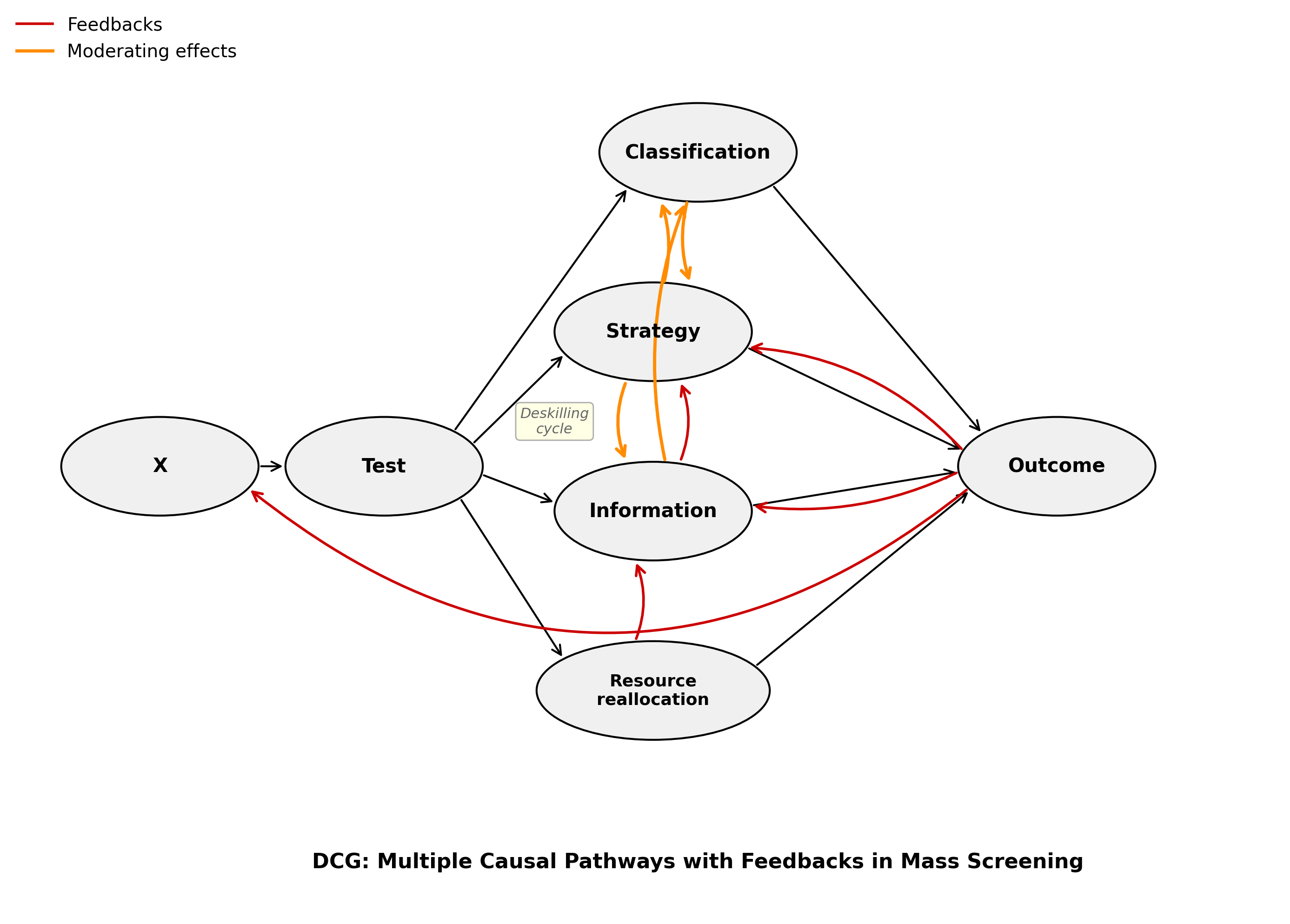
It’s a simplifying homo economicus error in an importantly messy, complex, irrational human world.

So what am I gonna do now with this app and the risk literacy leg of my research program that it was supposed to advance?
Let me proceed, as usual, to make the same mistake I study. To recap: Recently, I discovered, as a base rate neglect researcher, that large effects were rare in my own literature. Then, I realized that, as a student of the causal revolution who purported to have discovered an aggregation error in Fienberg’s NAS polygraph report, my causal model of polygraph programs themselves made aggregation errors (e.g., of dedicated and casual attackers along the strategy pathway).
What’s going on here? A generous read of this sort of error repetition might be that insight about pervasive cognitive and emotional biases comes and goes like colors in a kaleidoscope, shifting according to how we hold the tool, passing over different areas of our vision (including self-critical reflection) as we shift it in our hands (ideally over time) — reflecting learning and cumulative progress.
A harsher read might be that people are stupid, and I can, too!

Both of these reads dance on the surface of the insight that there is no exit from being puny mortals with limited and limiting perspective, a problem of non-neutrality that we should be explicitly mindful of as scientists in order to better science. This insight gives rise to an oddly hopeful despair, for which there is surely a long and unpronounceable German word like Schimmerhoffnungsverzweiflung, or (metaphorically) Schönheitstodschmetterling (“beautiful death butterfly”).
Because the science on programs of this structure is uncertain and we are (I am) hoping to improve it, eventually. But the risk communication cannot, should not, wait for the science to be settled. It will never (perhaps) be complete. Science is a process, not an institution; a practice, not a paper; a verb (albeit colloquial), not a single result. It’s not a problem that I’m doing science communication on unsettled science; it’s the job. Tikkun olam — the Jewish idea that you don’t have to finish the work, but you’re not allowed to abandon it.
So today we will be studying and making and unmaking and remaking homo economicus errors, and what they mean for telling people that we don’t know what to tell them exactly about interventions that might at first seem like a great idea, but may or may not actually be, but we still aren’t really sure just yet and may never be.
This is, admittedly, a much less persuasive argument than “Screening saves lives!”
Sciencing with Spock

Humans are strange. They don’t perform the essential cost-benefits calculations for most important choices. They get swayed by emotion instead. A lot. And sometimes this is forgettable, is forgotten, and must be reaccounted for. So says much behavioral economics (cf Tversky & Kahneman & Simon & bears, oh my), and also some more recent literature on the affect effect in risk literacy that I need to review here now.
The impetus: last month, I presented my risk literacy research to Prof. Odette Wegwarth’s group. Wegwarth is Heisenberg Professor for Medical Risk Competence at Charité Universitätsmedizin Berlin. She’s a long-time collaborator of Ralph Hertwig (Max Planck Institute for Human Development, who kindly referred me to her) and has published with Gerd Gigerenzer (who founded the Harding Center for Risk Literacy and is famous for building on Herbert Simon’s satisficing idea, the countermelody to the Kahneman, Tversky, Piattelli-Palmarini bias and error melody).
This is the tribe of natural frequency format Bayesian statistical teaching success, fact boxes, and generally boiling complexity down to make medical and other risk information actually legible to regular people (read: not statisticians), be they patients, pharmacists, or doctors.
A typical critique (e.g., of Wegwarth’s iWill Covid vaccine paper with Hertwig) is that there’s not enough perspective recognition in the heuristics, and so they are too deeply imbued with interpretation to be credible to their intended audience in a hyperpolarized world. In other words, it is really hard to not try to persuade with science communication, because it involves so much interpretation (like most of the rest of science).
But the alternative would seem to be perhaps more uncertainty acceptance and transparency about interests than most people actually want in their science communication. What if most people are really busy and just want to be told what to do, but the complex evidence doesn’t give directions and only interested parties are willing to oblige? (Then we get spin science and spin science communication, that’s what.) Bracket that.
The Charité discussion was among the most generative I’ve had on this project, and I’m grateful and excited to join the group as a Visiting Researcher in April to work up a grant proposal. With thanks to the whole group, but especially Prof. Wegwarth and Nikita Abalakin for the meeting and two of the Pachur papers summarized below, Miriam Rumpel for the iWill link and paper, and Ralph Hertwig for the introduction, here are some relevant readings.
tl;dr —
Hertwig, Barron, Weber & Erev (2004) — Prospect theory fails, people underweight rare events when they learn about risks from experience rather than description.
Hertwig & Erev (2009) — Description and experience produce opposite distortions for rare events. (Problem: Rarity Roulette tries to be a simulator but is really a passive description format; screening decisions are experience-based.)
Pachur, Hertwig & Steinmann (2012) — Direct experience (who you know who’s been affected) dominates frequency judgments; affect takes over for perceived risk and VSL (value of a statistical life). Media barely matters. (But maybe scaffolding can still help?)
Pachur, Hertwig & Wolkewitz (2014) — The affect gap: affect-rich contexts worsen decision quality and increase risk aversion (echoing a bunch of other widely accepted previous research on how threat, emotion, and time pressure degrade decision-making); in particular, people underweight probability information when outcomes feel emotionally loaded. The numerical spaghetti just slides right off the emotional wall.
Suter, Pachur & Hertwig (2016) — A third of people in affect-rich conditions don’t just weight probabilities badly; they abandon probability processing entirely, switching to minimax. Adding numbers doesn’t fix this. It’s a strategy?
Frank & Pachur (2024) — The affect gap holds robustly across age groups. This is a human thing, not an inexperienced youth thing or a cognitive decline thing (or, trust me to say the quiet part out loud, a hysterical woman thing).
Wegwarth, Ludwig, Spies, Schulte & Hertwig (2022) — Chronic pain patients randomized to simulated-experience vs. descriptive format for opioid risk (a best-case for solving the validation problem and having a “right answer” to objectively correctly push people towards behaviorally with good risk literacy work): simulation drove more behavioral change, description produced better numerical comprehension. The direct ancestor of iWill, and an empirical anchor for the group’s experiential design bent.
Wegwarth et al. (2023), JAMA Network Open — Interactive simulation beat conventional text for changing Covid vaccine-hesitant people’s vaccination intention and benefit-harm assessment to be more in line with the pro-vaccination consensus. Vaccine hesitancy is prime affect-rich decision territory. This is iWill. A risk literacy simulator that shows how to do the sort of scaffolding Perrett et al showed is necessary for good thinking, but on this terrain. More on this later.
Ralph Hertwig, Greg Barron, Elke U. Weber & Ido Erev. “Decisions from experience and the effect of rare events in risky choice.” Psychological Science, 15(8), 2004.
The original study: when people sample outcomes sequentially from two options and then choose between them, they behave as if rare events have less impact than their objective probabilities warrant. This is the opposite of what prospect theory predicts for description-based decisions, where people overweight rare events. The gap appears even when the objective information is identical. It’s driven by how people encounter it. Irrational people! Two candidate mechanisms: small samples (people just don’t draw enough to see the rare event) and recency (recent observations count more than earlier ones). The review paper below (Hertwig & Erev, 2009) synthesizes this finding across three paradigms.
Ralph Hertwig & Ido Erev. “The description–experience gap in risky choice.” Trends in Cognitive Sciences, 13(12), 2009.
Wouldn’t you think that experiencing rare events would make people weight them more heavily — just as you’d think experiencing suffering would make people more empathetic toward others suffering the same thing? But (small tangent here), Ruttan, McDonnell & Nordgren (2015) famously found the opposite: people who had overcome a hardship were harsher judges of others struggling with it than people with no relevant experience at all. Having survived made the experience seem more conquerable in retrospect, not more painful. Familiarity breeds contempt, not compassion — at least once you’re safely on the other side. Maybe that’s because we want to protect ourselves from how bad our own bad experiences really were. Maybe it’s because we’d prefer to make sense of the world as just and fair. Maybe we just forget what pain feels like at the time.
Whatever the emotional route of the empathy boomerang, Hertwig & Erev find that “in decisions from experience, people behave as if rare events have less impact than they deserve according to their objective probabilities, whereas in decisions from description people behave as if rare events have more impact than they deserve” — the latter consistent with cumulative prospect theory. So the two formats produce opposite distortions around rare events.
Early explanations focused on sampling error: maybe the gap is statistical, not psychological — people just encounter rare events less often in small samples. But the evidence didn’t fully bear this out. Psychological factors seem to be in play too, though which ones remain contested. Most relevant here: different formats give rise to different cognitive algorithms. Where rare events are implicated, description-based and experience-based decisions can drastically diverge.
Hertwig & Erev note something that sticks: a fully described world — the kind my tool provides, a complete frequency tree with all the numbers — is “both unattainable because of lack of information and a caricature.”
Among other things, it neglects that risk perception is shaped by personal experience. If risks are rare, a person mostly experiences their non-occurrence, generating less concern than the probabilities warrant. The sequential construction redesign (building the tree one event at a time) is an attempt to inject something closer to experienced sampling before the description format activates.
(Note: this doesn’t fully preclude rational Bayesian subgroup updating. Past experience can be informative — genetic risk, social network patterns. The gap isn’t always a bias; sometimes it’s people correctly updating on locally relevant base rates!)
Thorsten Pachur, Ralph Hertwig & Florian Steinmann. “How do people judge risks: Availability heuristic, affect heuristic, or both?” Journal of Experimental Psychology: Applied, 18(3), 2012.
Overall: availability-by-recall (exploiting direct experience of risks in one’s social network) conformed to people’s responses best — beating affect on accuracy for both frequency judgments and VSL. But affect comes in when instance knowledge doesn’t discriminate, or “when the specific risk measure conjures up an image of an individual case.” The human interest story effect.
One finding worth flagging: media exposure doesn’t appear to shape risk estimation in their study. That’s somewhat reassuring! It means people who’ve been exposed to a lot of pro-screening messaging aren’t necessarily locked in by it. Direct experience is the stronger lever.
There’s also a structural limit: direct experience is most likely available for common risks and lacking for rare risks. This is a problem for mass screenings: the very rarity of the target condition means most people’s social network experience is near-zero for true positives, but non-zero for the harms of false positives. But they don’t know thye’re false positives. So this would suggest availability-by-recall may actually support the RR argument, if we can help people access their own or their network’s experiences with false positives and overtreatment rather than with the scary headline outcomes.
But how to do that? False positives have quite vested interests in not thinking they may have been false positives. This perpetuates bad feedback loops that support screening in spite of possible net harm from false positives.
The next two papers, more than any others here, seem to explain why Rarity Roulette has struggled.
Thorsten Pachur, Ralph Hertwig & Roland Wolkewitz. “The affect gap in risky choice: Affect-rich outcomes attenuate attention to probability information.” Decision, 1(1), 2014.
This is the paper that named the affect gap. The setup: affect-rich outcomes (medical side effects described with emotional language) vs. affect-poor outcomes (equivalent monetary losses). People in affect-rich conditions showed systematically worse decision quality — lower sensitivity to probability information, more risk aversion — compared to the affect-poor condition. The gap persisted even when the objective expected values were identical. (Again this is not sui generis; I cited other research on much the same effect in my dissertation that I defended, embarrassingly, before this was published.)
The mechanism proposed: affect-rich outcomes capture attention and cognitive resources, leaving less available for probability processing. This is distinct from simple probability distortion; it’s a resource allocation problem. People aren’t weighting the probabilities wrong; they’re not weighting them much at all.
For Rarity Roulette: screening decisions are very affect-rich. Cancer, diagnosis, surgery, chronic pain. Imagine your death, then try to do math! Pachur et al predicts that presenting well-designed frequency information into an affect-activated state will underperform. Not because the format is wrong, but because the cognitive resources needed to process it are occupied elsewhere.
This is why the entry point is load-bearing. It was suggested to shift people into a cooler cognitive state before the emotionally loaded content appears. Ask if they’re aware the programs may cause harm as well as benefit. Try to give them awareness of a solvable problem. And then really scaffold, step by step, how to solve it.
Renata S. Suter, Thorsten Pachur & Ralph Hertwig. “How affect shapes risky choice: Distorted probability weighting versus probability neglect.” Journal of Behavioral Decision Making, 29(4), 2016.
The affect gap more precisely: in affect-rich choices (medical contexts), a third of participants stopped using probabilities at all — switching to minimax (avoid the worst-case outcome regardless of probability) rather than probability-weighted reasoning. In affect-poor contexts, 95% used CPT-style probability weighting. Crucially: adding explicit numerical information didn’t fix this. The affect gap is not a formatting problem. It’s a cognitive strategy shift.
This is the paper that should have made me nervous before Pilot 1. A non-trivial fraction of my participants may have looked at the frequency trees and simply not processed them as decision-relevant. Not because the format was wrong, but because the emotional salience had already switched them to a different strategy. And this clarifies why PPV comprehension remains the right DV: the goal is to check whether the entry point and sequential format successfully shift people into frequency mode before affect takes over. If they’re in frequency mode, they can compute PPV. That’s what we want to measure, and it’s value-neutral.
Colleen C. Frank & Thorsten Pachur. “The affect gap in risky choice is similar for younger and older adults.” Psychology and Aging, 2025.
Same mechanism in younger and older adults: lower probability sensitivity and greater risk aversion under affect-rich conditions. One nuance: younger adults showed a spotlight effect (affect made outcome magnitudes feel larger); older adults showed similar outcome sensitivity regardless of context, consistent with gist-based processing. Given that the target population for screening decisions skews older, the affect gap won’t shrink with age.
Odette Wegwarth, Wolf-Dieter Ludwig, Claudia Spies, Erika Schulte & Ralph Hertwig. “The role of simulated-experience and descriptive formats on perceiving risks of strong opioids.” Patient Education and Counseling, 105(6), 2022.
I’m including this because it’s the Charité group’s own empirical anchor for why they take sequential/experiential design seriously, and the direct ancestor of iWill. Chronic noncancer pain patients were randomized to simulated-experience format vs. descriptive format for opioid risk information. The simulated-experience format drove more behavioral change; the descriptive format produced better numerical comprehension. That dissociation — knowing the numbers vs. acting differently — is exactly the tension at the heart of Rarity Roulette. It also maps onto a believers/knowers distinction Wegwarth made during the meeting that sits heavily on my heart: knowers may get more from the descriptive format’s numerical precision; believers may need the experiential format’s behavioral nudge. Who wants to know? Can we reach people who don’t want to know? Should we be trying?
Odette Wegwarth, Uwe Mansmann, Florian Zepp et al. “Vaccination intention following receipt of vaccine information through interactive simulation vs text among COVID-19 vaccine–hesitant adults during the Omicron wave in Germany.” JAMA Network Open, 6(2), 2023.
The same group’s most recent large-scale application of the description-experience gap framework: 1,255 COVID-19 vaccine-hesitant adults randomized to interactive simulation vs. text-based information during the Omicron wave in Germany, recruited through a probability-based internet panel. Vaccine hesitancy is about as affect-rich a decision context as you can find, and the simulation worked anyway.
The simulation was associated with greater positive change in vaccination intention (19.5% vs 15.3%; absolute difference 4.2%; aOR 1.45, 95% CI 1.07–1.96) and benefit-harm assessment (32.6% vs 18.0%; absolute difference 14.6%; aOR 2.14, 95% CI 1.64–2.80). The data are compatible with the simulation producing between 7% and 96% greater odds of positive vaccination intention change, and between 64% and 180% greater odds of positive benefit-harm reassessment. Net advantage after accounting for negative changes: +5.3pp for vaccination intention (9.8% vs 4.5%) and +18.3pp for benefit-harm assessment (25.3% vs 7.0%).
This suggests an empirical case that the design principle works at scale and in a real-world public health context. It’s the primary reason I want to collaborate with this group on my risk literacy research. But it’s also why I’m thinking of abandoning Rarity Roulette.
Conclusion
What does this all mean about science communication on mass screenings for low-prevalence problems?
The bad news for Rarity Roulette is that there is a case for building very serious scaffolding to help people enter thinking about these programs from a cognitive state where they might actually be able to reason logically and probabilistically, and do so — and that likely means building a very different user experience from scratch.
iWill exemplifies this approach.
But I am still struggling with the non-neutrality problem in implementing something like it on my own terrain: which risks to foreground, how to represent uncertainty, how not to smuggle in a conclusion under the guise of clarity.
The deeper problem is not mainly where the false positives text sits or whether the tree appears sequentially; the problem is that I am no longer sure the app’s underlying task matches the epistemic task I care about.
If the goal is computation — helping people calculate PPV — then frequency trees, sequential construction, and careful scaffolding all make sense. But if the goal is perspicacity — recognizing when base rates dominate, noticing when a screening program might plausibly incur net harm, understanding the structure of the problem before anyone asks you to calculate anything — then it is much less clear that more or better computation is the right lever.
The good news is that there is still a case for keeping PPV calculation (perhaps even explicitly LLM-assisted) as a dependent variable. It is at least value-neutral and checks comprehension rather than behavior, which matters because we usually cannot agree on what the “right” decision is in these domains. Some people will rationally choose screening after understanding the numbers; others will not. A measure that treats one of those as failure is not acceptable.
So Old Rarity may not be a prototype to refine so much as a wrong turn that clarified the question. The work ahead may be less about fixing this particular interface and more about deciding what, exactly, the interface should be trying to do — and then doing it a lot more slowly, with a lot more scaffolding for users.
For now, that seems like a problem worth thinking about slowly. To harken back to a recent found illustration of the problem, the photo up top: not everyone wants to know the truth (much as not everyone wants to drink straight whiskey). Old Rarity might require some mixing, some baking — or tossing down the drain.
The idea is to eventually alert people to the base rate fallacy with some interface that will let them bring their own values in, make their own interpretations, and take away the Bayesian statistical intuition that programs of this structure may incur net damage rather than net benefit — but to situate that insight in the larger context of complexity and persistent uncertainty that’s really very uncomfortable for us all.
L’chaim.
References
Ralph Hertwig, Greg Barron, Elke U. Weber, & Ido Erev. (2004). Decisions from experience and the effect of rare events in risky choice. Psychological Science, 15(8), 534–539. Original study.
Ralph Hertwig & Ido Erev. (2009). The description–experience gap in risky choice. Trends in Cognitive Sciences, 13(12), 517–523. Readable review.
Thorsten Pachur, Ralph Hertwig, & Florian Steinmann. (2012). How do people judge risks: Availability heuristic, affect heuristic, or both? Journal of Experimental Psychology: Applied, 18(3), 314–330.
Thorsten Pachur, Ralph Hertwig, & Roland Wolkewitz. (2014). The affect gap in risky choice: Affect-rich outcomes attenuate attention to probability information. Decision, 1(1), 64–78.
Renata S. Suter, Thorsten Pachur, & Ralph Hertwig. (2016). How affect shapes risky choice: Distorted probability weighting versus probability neglect. Journal of Behavioral Decision Making, 29(4), 437–449.
Colleen C. Frank & Thorsten Pachur. (2025). The affect gap in risky choice is similar for younger and older adults. Psychology and Aging. [Preprint]
Rachel Ruttan, Mary-Hunter McDonnell & Loran Nordgren. (2015). When having "been there" doesn't mean I care: When prior experience reduces compassion for emotional distress. Journal of Personality and Social Psychology, 108(4), 610–622.
Odette Wegwarth, Wolf-Dieter Ludwig, Claudia Spies, Erika Schulte, & Ralph Hertwig. (2022). The role of simulated-experience and descriptive formats on perceiving risks of strong opioids: A randomized controlled trial with chronic noncancer pain patients. Patient Education and Counseling, 105(6), 1571–1580.
Odette Wegwarth, Uwe Mansmann, Florian Zepp, et al. (2023). Vaccination intention following receipt of vaccine information through interactive simulation vs text among COVID-19 vaccine–hesitant adults during the Omicron wave in Germany. JAMA Network Open, 6(2), e2256208.