
It's the Analysis, Stupid
Accuracy is often the focus in discussions of program efficacy, but whether mass screenings "work" depends on how we analyze their data

“Pride comes before a fall” (Proverbs 16:18). So goes the structure of classical Greek tragedy. Or, more precisely: arete (virtue), hubris (arrogance), ate (fatal mistake), nemesis (divine punishment).
Modern screening programs often follow the same arc.
Virtue — we want to catch the baddies (spies, pedophiles, deadly cancers). Hubris — tech can solve it; a man-made innovation can change the structure of the universe, escaping the consequences of imperfection and frailty. Fatal mistake — applying imperfect screening tools to whole populations when secondary screening doesn’t adequately disambiguate true from false positives and carries costs. And the fall — the accuracy-error trade-off stemming from Bayes’ Rule in probability theory generates either unacceptable numbers of false positives, or unacceptable numbers of false negatives, both of which may stack up in the form of massive, invisible societal net damage.
But there is always another wrinkle to unfold, another layer of this problem to worry like rosary beads of the mind. It’s not only the straightforward implications of the universal laws of mathematics that punish our hubris. It’s also the more complex analyses we use to assess whether these programs work.
Even when we have good data on screening programs, we often analyze it in ways that produce systematically wrong answers. And then policy is made — policy that looks relatively evidence-based! — on those answers. This is a different kind of hubris: not imagining that we can escape the laws of probability with better tech (Technosolutionism). But imagining that we can make causal inferences without carefully thinking through what question we’re actually asking and how to answer it logically (if indeed we can).
Let’s look at how these analytical troubles can plague us in a case study of gold-standard experimental data on a mass screening for a low-prevalence problem, colonoscopy for colorectal cancer.
NordICC and the Analysis Problem
In 2022, the NEJM published results from the NordICC trial (Bretthauer et al., 2022), the first randomized trial of colonoscopy screening for colorectal cancer. Results suggested a small to modest CRC incidence risk reduction of about 7-30%, and an uncertain effect on all-cause mortality.
This finding is not dissimilar from many mammography trial findings; the inability to prove all-cause mortality benefits is persistent. One could read that type of result as quite damning for the screenings, given how much data have been collected on them across time and space. I sometimes have. But it really is just an unknown — and an open invitation to maybe someday knowing.
I’ve written about NordICC before: On the difficult ambiguities in what it means to count the bodies in screening research like this, and on what the trial evidence does and doesn’t establish about colonoscopy’s possible mortality benefit.
Here’s a different angle: the trial found an 18% CRC risk reduction. That is, the intention-to-treat (ITT) risk ratio for CRC incidence is 0.82 (95% CI 0.70–0.93), meaning the data are consistent with anywhere from a 7% to a 30% reduction in CRC incidence among those invited to screening.
But that’s an intention-to-treat estimate. It estimated the effect of being invited to colonoscopy on a population where only about 42% subsequently got screened.
The per-protocol estimate, restricted to those who actually then underwent colonoscopy, was considerably larger. (As usual, the problem stems from that pesky free will; researchers could randomize the invitation, but not the uptake.)
Similarly, in the ITT analysis, the trial found no certain effect on all-cause mortality (95% CI 0.96–1.04, consistent with up to a 4% reduction or increase). On colorectal cancer mortality specifically, ITT data are consistent with anywhere from a 36% reduction to a 16% increase (95% CI 0.64–1.16). In absolute terms, the observed difference was 3 fewer colorectal cancer deaths per 10,000 people, possibly due to chance. The number needed to invite to prevent one colorectal cancer case ranged from 270 to 1,429.
But NordICC’s own adjusted per-protocol analysis told a different story: an estimated 31% reduction in colorectal cancer incidence (RR 0.69, 95% CI 0.55–0.83) and a possible 50% reduction in colorectal cancer mortality (RR 0.50, 95% CI 0.27–0.77) — meaning the data are consistent with anywhere from a 23% to a 73% reduction among those who actually got screened. It appears that Bretthauer et al did not include a per-protocol all-cause mortality estimate despite this dependent variable being pre-specified as a secondary endpoint.
A 2024 reanalysis by Meirson, Markel, & Goldstein applying survival methods found no mortality benefit even in per-protocol. The data are consistent with anywhere from a 51% reduction to a 7% increase in time lost to CRC death. We're still waiting for the 15-year follow-up data.
So we still don’t know what we most want to know: whether the screening saves or prolongs lives, net of harms, under current conditions. And we still haven’t got a neat experimental dataset, even though Bretthauer et al. ran an experiment. Because we can’t randomize away free will in medical decisions. So we still have this ITT versus per-protocol analysis difficulty to attend to in analyzing the data.
This is the sort of problem Vanessa Didelez’s work addresses.
Of Broken DAGs, Dynamic Processes, and Scaffolding for Inference
The long and winding road that leads us here has most recently examined why DAGs can break when causal mechanisms operate continuously over time, reviewing work by Odd Aalen, Jon Michael Gran, and colleagues. Then, we looked at what happens when phenomena react to being modeled, when aggregating across levels destroys the causal structure of interest, and how scaffolding might help. Both posts arrived at the same gap: the usual tools for causal inference in screening contexts weren’t built for feedback, for dynamic causal processes, for the system-level behavior that might drive the net effects we care about.
Vanessa Didelez and her collaborators have begun building the methodological machinery to fill that gap. Didelez is Professor of Statistics and Causal Inference at the University of Bremen and the Leibniz Institute for Prevention Research and Epidemiology (BIPS). She’s also Gran and Aalen’s co-author on this problem (Gran, Røysland, Wolbers, Didelez, Sterne, Ledergerber, Furrer, von Wyl & Aalen, “A sequential Cox approach for estimating the causal effect of treatment in the presence of time-dependent confounding applied to data from the Swiss HIV Cohort Study,” Statistics in Medicine, 2010).
Tangentially, Didelez developed foundational work on Mendelian randomization as an instrumental variable approach to causal inference (with Nuala Sheehan, Statistical Methods in Medical Research, 2007, see also the Royal Statistical Society talk “Nature does play dice!”). The idea: when you can’t randomize people to an exposure (say, higher LDL cholesterol), you can sometimes use a gene variant as a natural instrument — something that affects the exposure but has no direct path to the outcome and isn’t associated with confounders because Mendel’s laws of inheritance randomize it independently at conception. So the gene stands in for the experiment Nature won’t let you run. Didelez and Sheehan gave this intuition a formal causal framework with DAGs.
Wait! Einstein said “God does not play dice with the universe,” objecting to quantum indeterminacy. But, as Didelez and Sheehan joke in their RSS talk title, “Nature does play dice!” when it comes to chromosomes: Mendel’s laws of inheritance randomize alleles independently at conception, uncorrelated with lifestyle or environment. That’s what makes genetic variants usable as instrumental variables for causal inference. However, this same individual-level randomness also produces population-level order and robustness to unforeseeable population-level genetic disasters (Hardy-Weinberg equilibrium). This is potentially consistent with the watchmaker analogy: maybe God has Nature play dice with chromosomes, because He doesn’t play dice with the universe.
What Fresh MacGyver?
So Mendelian randomization is one MacGyver move: use what Nature gives you (the genetic lottery) as a stand-in for the experiment you can’t run. Didelez & co’s logic for screening evaluation is similar: you can’t randomize people to decades of mammography. You can’t withhold colonoscopy from a control group for ten years. But you can specify, precisely and in advance, what that randomized trial would have looked like — who would have been eligible, what the treatment strategies would have been, how outcomes would have been measured — and then emulate that target trial using observational data.
Target trials aren’t some sloppy shortcut. They’re a way of imposing the discipline of trial design on observational analysis, so that the question being asked of the data is actually the question we want to answer.
But in order to validate whether that structure really gives us the right answer, we need something beyond one application of the framework. Analogizing to real-world trials, we would need to see the distribution of results from many such target trial analyses of related datasets, just as we would need to see many randomized trials to assess the distribution of results and begin to make inferences about where the true effect probably lies.
So What About Mammography?
Mammography has been evaluated in more randomized controlled trials, across more countries and decades, than any other cancer screening. Yet, we still don’t know if it works. Neither in the sense of saving lives; all-cause mortality benefit is uncertain. Nor in the sense of improving quality of life; rather, much research suggests it may actually degrade it by creating large numbers of false positives subject to invasive, painful, scary secondary screening and intervention with zero benefit.
Among skeptics, therefore, it is considered a persistent science communication problem that many clinicians and patients do not understand this to be the state of the evidence; belief that “screenings save lives” is widespread and strong, particularly among people who have themselves been false positives. This is easily emotionally understandable: the stakes are human power to fight back against frailty, disease, and death with science; trust in the institutions and experts who achieve that god-like feat; and rejection of the possibility that we have got it wrong and suffered greatly for no good reason but ignorance, and maybe someone else’s profit.
Among believers, however, it is considered unethical to question contested findings that show meaningful early detected cancer-specific mortality benefits alongside minimal overdiagnosis. The field is divided. The evidence is ambiguous.
I used to find this very damning, but now see my own past judgment in that regard as just another instance of pervasive cognitive biases linked by uncertainty aversion: we don’t know, so I think we should maybe act like it doesn’t work because we can’t provably justify the cost (which may include substantial quality of life loss to a large number of women). But what if it net saves a lot of lives, and most people would take that trade? The abiding uncertainty about all-cause mortality benefits matters. So, too, do value differences that make finding “the answer” to the question of whether it works impossible; different people will have different answers to questions like, would you trade a small chance of a breast cancer death for a 3x or more greater chance of unnecessary treatment that’s the worst experience of your life?
All this is just to say that doing the analysis better isn’t going to necessarily answer the question of whether mammography screening programs are a good idea, or not. But it might help us figure out whether previously demonstrated breast cancer-specific mortality benefits (from decades-old randomized trials) are still current today. Since then, after all, treatments have improved dramatically, especially for advanced cancers. Imaging technologies have improved. And populations have changed in their composition and behavior. So those old trials don’t establish mammography screening’s effects today. This so-called effectiveness gap isn’t unique to mammography. It’s innate to any intervention evaluated by trials conducted under conditions that no longer obtain.
Didelez & co have been building the formal machinery to estimate these effects from observational data. Their solution, in a 2022 protocol paper by Braitmaier et al, is target trial emulation: specify the randomized trial you wish you could run, then emulate it using observational data. Using German health claims data covering approximately 37.6 million individuals, they emulate trials comparing three strategies — no screening, screening at baseline only, and sustained biennial screening.
The methodological backbone is a “cloning” approach: each woman’s data is copied and assigned to every screening strategy consistent with her observed behavior at baseline, then artificially censored at the moment her actual behavior diverges from the assigned strategy. It’s a principled solution to immortal time bias, the systematic error that creeps in when people who survive long enough to receive a treatment get incorrectly credited with having better outcomes simply because they survived long enough to have them.
This is, to Braitmaier et al’s knowledge, the first observational study on mammography effectiveness to use target trial emulation — a design notable for its explicit pre-registration of the full analytic protocol before outcome data were available, still far from standard practice in observational epidemiology. Results were presented in July 2025 at a federal government event in Berlin (Bundesamt für Strahlenschutz, 2025), and they were impressive. Among women who participated in screening, breast cancer mortality declined by 20–30% based on 2009–2018 data. The finding will be interpreted against the formal causal framework the protocol specified in advance.
Caveat: Most German health claims data don’t identify breast cancer deaths as such; direct cause-of-death linkage is available only for women in three federal states. In all the other states, these deaths are identified via a validated algorithm (sensitivity 91.3%, specificity 97.4%) using claims codes in the year of death. So this analysis may warrant replication in datasets where these deaths are better identified.
Confounding, Censoring, and Bears, Oh My
Two methodological challenges sit at the heart of any target trial emulation of a screening program. The first is confounding: people who choose to screen differ systematically from those who don’t, tending to be healthier, more health-conscious, and better resourced (the classic healthy user/volunteer bias). The second is artificial censoring: when someone deviates from their assigned strategy over time (e.g., stops attending regular screening), their data has to be dropped from that arm, which can itself introduce bias if the reasons for deviation are related to outcomes (e.g., relevant illness).
The Braitmaier group handles both through a combination of inverse probability weighting and a carefully constructed comparison population. For their primary confounding analysis, they define a subgroup of “screening-affine” women* as those who used at least one other preventive service (pap test, health check-up, colonoscopy, flu vaccination, and similar) in the three years before baseline. The logic: women who engage with preventive healthcare generally are a more internally valid comparison group for assessing the decision to screen specifically, because the comparison is less contaminated by general health-seeking behavior. It trades some generalizability for substantially better internal validity.
(* “screening-affine” is a German-English hybrid — from the German affin, meaning naturally inclined toward something — that reads as pleasantly odd jargon in English, resonating with “affinity.” Meaning, women who already engage with preventive healthcare generally: healthy users.)
The severity of this problem has been empirically demonstrated. For instance, Lousdal et al. (2020) found that mammography screening participants had substantially lower death risks from external causes — outcomes the screening cannot plausibly affect — suggesting that healthy user bias remains after standard covariate adjustment.
One last caveat: Target trial emulation is a major advance in how we think through causal questions — it applies the logic of the causal revolution to observational data in a disciplined, bias-aware way. But this is still observational data. The method imposes the structure of a trial; it doesn’t create one. Unmeasured confounding can’t be ruled out.
However, as Stephen Senn and others have argued, randomization also doesn’t guarantee balance on unmeasured confounders in any single trial. It just makes such bias unlikely to be systematic in expectation over multiple trials. The gap between an emulated and an actual trial is real, but it may be smaller than critics assume and larger than proponents claim. The important thing may be to insist on replication in both contexts, to try to get a fuller picture of the hypothetical distribution of results from which each study is just one draw.
Anyway, the assumptions required for identification here are untestable. Things like: no unmeasured confounding (everyone who could have been in either arm had some probability of being there, and all relevant differences between them are measured and adjusted for), positivity (there are actually people in the data who followed each strategy being compared), and consistency (the “treatment” is well-defined enough that the potential outcome under a strategy matches what actually happens when people follow it).
Assumptions about these things are untestable, because they’re claims about the data-generating process — about what would have happened under conditions that didn’t occur. You can check whether your measured covariates look balanced. You can check whether there are people in both arms. But you cannot check whether there are unmeasured differences between screeners and non-screeners that your adjustment didn’t capture, because by definition you didn’t measure them. The assumption of no unmeasured confounding is a claim about unobservables.
This is, of course, not unique to target trial emulation. It’s a fundamental epistemological problem of causal inference. Randomization sidesteps it — imperfectly, involving still human interpretation at many points of observation, analysis, and results reading. Randomization in one trial doesn’t guarantee anything about the distribution of relevant confounds, and randomization across many trials doesn’t guarantee anything about the distribution of relevant confounds given that people still have that pesky free will and can do as they please. So, science generally still requires some assembly.
Furthermore, as the colonoscopy case highlights, a new method that produces different results from previous studies is not automatically right. It might be correcting for real biases, it might be introducing its own, or both. Braitmaier et al 2022 found no difference in colonoscopy screening effectiveness between detecting distal and proximal colorectal cancers, contradicting years of prior observational findings. Their argument is that the earlier studies were artifacts of immortal time bias and selection effects that target trial emulation corrects for. That may well be the case. But the finding that a new analytical approach erases a previously consistent result is something to note with interest, not just accept. The method is better. Better isn’t the same as certain.
The Analysis Artifact: The Colonoscopy Lesson
Back to colonoscopy. The NordICC confusion had a precursor. For years, observational studies had found that colonoscopy appeared less effective at preventing proximal colorectal cancers (in the right colon) than distal ones (in the left colon and rectum). This was taken as a true signal — maybe the right colon was harder to visualize, maybe polyp biology differed.
A 2022 paper by Braitmaier, Schwarz, Kollhorst, Senore, Didelez, and Haug suggests the finding was largely an analytical artifact. Using the same target trial approach — emulating a randomized trial with German claims data, in approximately 307,000 people aged 55 to 69 — they found that colonoscopy reduced 11-year colorectal cancer incidence by about 32% overall, and that the reduction was similar for both distal and proximal cancers. Unlike earlier observational studies, they found no meaningful difference by tumor location.
Braitmaier et al argue that the discrepancy with previous studies isn’t biology. It’s that observational studies of colonoscopy are riddled with time-related biases — particularly immortal time bias and selection effects — that the target trial approach corrects for. The “colonoscopy doesn’t work for proximal cancers” finding has been shaping clinical guidelines and patient counseling for years. It may have been wrong. And it may have been wrong not because the underlying data were bad, but because of how the data were analyzed.
This is the analysis problem. It’s downstream of the math problem I’ve written about elsewhere. Even after you understand why base rates punish mass screenings for low-prevalence problems and people tend to be blind to this (base rate blindness); even after you’ve accepted that no test is accurate enough to escape probability theory at population scale, so we have to assess the practical importance of false positives and false negatives; you still have to analyze your data correctly to learn anything useful about what works.
An illustrative comparison: NordICC found colonoscopy screening invitation was consistent with anywhere from a 36% reduction to a 16% increase in colorectal cancer mortality (95% CI 0.64–1.16), with no certain all-cause mortality benefit. By contrast, Braitmaier and Schwarz’s target trial emulation found colonoscopy reduced 11-year colorectal cancer incidence by 27–37% among people who actually got screened (RR 0.68, 95% CI 0.63–0.73). The second interval is tighter and more optimistic. But it’s measuring something different: incidence not mortality, compliant screeners not everyone invited, emulated trial not randomized one.
These aren’t contradictory results. They’re answers to different questions. That’s the larger problem: most of the confusion in screening evaluation isn’t about what the data can be said to suggest. It’s about which question was asked, and whether anyone noticed that different studies were asking different ones.
Asking the right question (if there is one) is necessary but not sufficient. We also need a framework rigorous enough to answer it.
The Formal Foundation: Causality Without Counterfactuals
The theoretical machinery underlying both the mammography and colonoscopy work reaches back to a 2010 paper by Dawid and Didelez (“Identifying the consequences of dynamic treatment strategies: A decision-theoretic overview,” Statistics Surveys, Vol. 4, p. 184-231).
Most causal inference frameworks, and most of our intuitions about causality, rely on counterfactuals, like: what would have happened to this person if they hadn’t been screened? This is philosophically awkward (we can never observe counterfactuals for individuals) and practically limiting (it doesn’t generalize naturally to sequential decisions over continuous time).
Didelez’s alternative, developed with University of Cambridge Emeritus Statistics Professor and leading Bayesian statistics proponent A. Philip Dawid, and formalized in earlier solo work (“Graphical Models for Marked Point Processes Based on Local Independence,” Journal of the Royal Statistical Society Series B: Statistical Methodology, Vol. 70, No. 1, Feb. 2008, p. 245–264) reframes the question. Didelez was building on a concept Aalen developed: represent causal structure not between static variables but between ongoing event processes, where an edge from A to B means A’s past helps predict B’s short-term future intensity.
The separation criterion Didelez developed for these graphs, δ (”delta”)-separation, is the analogue of Pearl’s d-separation for local independence graphs — built specifically to handle the asymmetry that local independence introduces. Unlike d-separation, it’s directional: A not predicting B’s future doesn’t imply B not predicting A’s. That asymmetry is the formal innovation.
Didelez frames this as the continuous-time analogue of Granger non-causality — the idea from econometrics that X “Granger-causes” Y if knowing X’s past improves your forecast of Y’s future, beyond what Y’s own past already tells you. Local independence says the same thing, but for event processes unfolding in continuous time rather than discrete time steps.
Instead of asking what would have happened to an individual under different treatment, you ask what happens in a system where the intensity of a treatment process is set to different values. You’re intervening on intensities — rates at which events occur — rather than on individual trajectories. The causal question becomes: what is the difference between a world where screening intensity follows policy A versus policy B?
This matters for three reasons: First, it’s more general; it handles continuous-time processes naturally, rather than forcing the world into discrete time slices. Second, it sidesteps metaphysical debates about individual counterfactuals. And third, it maps directly onto what policymakers can actually do: we can change screening protocols; we can’t change individual pasts.
The continuous-time formalization also handles something my four-pathway model describes but doesn’t formalize: that screening systems involve sequences of decisions over time, not single binary screen/don’t-screen choices. Readers may recall that previously, I wrote about σ-separation — the analogue of d-separation for directed cyclic graphs, which handles feedback loops that break DAGs. Didelez’s δ-separation is a related but distinct move: it generalizes d-separation not for cyclic graphs, but for the asymmetric dependence structures that arise in continuous-time event processes. Different problem, different formalism, same underlying impulse: when acyclic assumptions break, we need new separation criteria. So Didelez built one.
An example: Imagine tracking four processes for an elderly person over time — nurse home visits, hospitalisation, underlying health status, and death (Didelez, p. 9). The visits are scheduled externally: nurses come when available, not in response to the patient’s condition. So visits are locally independent of health and hospitalisation. And survival is locally independent of visits given hospitalisation and health history. Clean graph, clean story. So drop health status from the model? It is, after all, hard to measure correctly/completely. And it doesn’t matter, right?
Wrong. If you drop it, then suddenly, visits and death look dependent, even though visits don’t directly affect survival and weren’t even responding to health in the first place. Why?
If the nurse visits and then the patient goes to hospital, it means the patient condition was so bad that a nurse home visit couldn’t prevent the hospitalization. Health status was doing explanatory work. So ignoring it lets visit history sneak back in as a spurious predictor of death.
This is the problem the screening-affine subgroup analysis is designed to address. We can’t measure everything. But if we don’t model which unmeasured processes matter, and condition on the right ones, we’ll find dependencies that aren’t there, and miss ones that are.
The effects then propagate through the system dynamically — a decision to screen at one time point changes the probability distribution over later events in ways that are only capturable in a framework that takes time seriously.
Overdiagnosis, Competing Risks, and Unavoidable Trade-offs
There’s one more piece of the formal apparatus worth understanding: the problem of competing events.
Screening for cancer mortality faces a fundamental complication. People can die of other causes before a detected cancer would have killed them — or before it would ever have become symptomatic. A screen-detected cancer is “overdiagnosed” if the person would have died of something else first. This isn’t merely a theoretical concern; overdiagnosis is a real and significant harm of screening programs, representing treatment burden imposed on people for conditions that would never have affected their lives.
But how do you define the causal effect of screening on cancer mortality when competing mortality is always in the background? Standard mediation analysis — decomposing treatment effects into direct and indirect pathways — runs into trouble here because the standard approach relies on “nested counterfactuals” that become incoherent in survival analysis settings.
A 2022 paper by Stensrud, Young, Didelez, Robins, and Hernán proposes separable effects as a solution. The key move: instead of relying on nested counterfactuals, you explicitly specify the mechanisms you want to separate, and you formalize that separation using an augmented directed acyclic graph. Under assumptions about separability, identification of the mediated effects becomes possible and recovers something like the familiar mediation formula — but without requiring unobservable individual-level counterfactuals, and grounded throughout in decision theory. The Norway cancer screening work that Didelez conducted with Røysland and Aalen applies related tools to real data, closing the loop between theory and application.
What’s Still Missing
Didelez’s body of work provides formal tools for moving from “does this test have good sensitivity and specificity?” to “does this screening program reduce early-detected cancer-specific mortality under current conditions?” That’s a major advance. The tools — target trial emulation, decision-theoretic causal inference without counterfactuals, local independence graphs, continuous-time inverse probability weighting, separable effects for competing risks — add up to a coherent framework for estimating those effects.
But none of these tools, as currently applied, decomposes net effects into pathway-specific contributions. Target trial emulation compares protocols — it asks whether strategy A beats strategy B in terms of mortality — but it doesn’t tell you how much of that difference comes from better classification, how much from changed clinician / health system behavior, how much from information effects on patients, or what things might look like with different resource reallocation. The net effect is estimated. The mechanism isn’t specified. If the mechanisms doing the work are ones other than the test, then why not chuck the test (with its false positive carnage) and keep the pathways that cause the benefits?
To recap, I’ve been developing a framework formalizing the insight that classification accuracy is only one of four causal pathways through which screenings like colonoscopy and mammography affect outcomes — alongside strategic, information, and resource reallocation effects. I came to this puzzle from political science with a focus on security screenings, and I’ve mostly been making the argument descriptively and via simulations. But the real-world data to make it quantitatively seem to be accessible in medicine*, not in security.
(*Sort-of. The data in medicine on these screening programs is great, especially in Scandinavia, Taiwan, and Japan. And, unlike in security, independent evaluators can often access said data. However, these pathways may yet only be decomposable on the basis of simulations packed with assumptions in any domain. But then at least we can make claims about having partly solved the validation problem in some medical case studies, unlike in most security case studies where we can’t get at ground truth to visualize the ROC space in real life.)
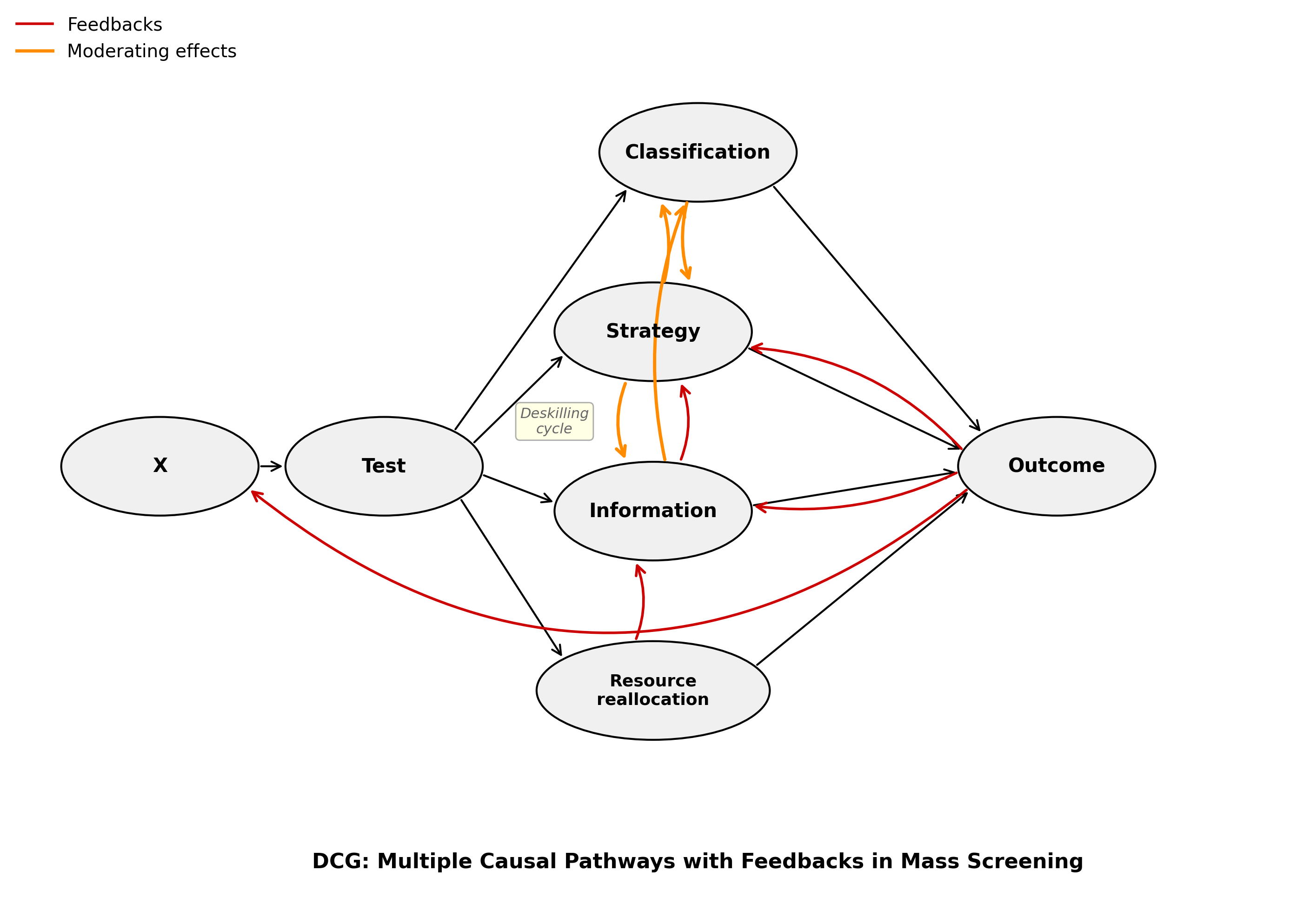
Making this four-pathway decomposition more empirically tractable — even partially, even approximately, even with many caveats — is what I think requires combining Didelez’s formal machinery with cross-domain comparison and explicit modeling of the pathways separately.
This isn’t just a theoretical aspiration. The Stensrud et al. separable effects framework is already a step toward pathway decomposition — it separates the effect of screening operating through true early detection from the effect operating through competing mortality displacement. That’s the beginning of the classification/resource reallocation decomposition. The rest requires more.
Strategic effects — how protocol design, clinician incentives, perverse incentives (e.g., medical system profit), and system-level behavior shape who gets screened, how, and with what follow-up — are partly captured by target trial emulation when it compares protocols. But that framework doesn’t separate “this protocol works because the test is good” from “this protocol works because it brings women into contact with better care infrastructure.” Mette Kalager’s 2017 observation that mammography’s benefits might come from peripheral elements — quality assurance, care pathways — rather than the screening itself, works along this dimension.
Information effects — iatrogenesis from radiation, surgery, and cascade diagnostics; anxiety from false positives causing different health and health system behavior — operate through channels that aren’t captured by mortality endpoints alone, and that may have opposite-signed effects running simultaneously.
Resource reallocation effects — what we could have researched, funded, or implemented instead — require comparison classes that no target trial framework naturally supplies, because target trials compare screening strategies to each other, not to the counterfactual world where those resources went elsewhere.
This is where cross-domain comparison might contribute something. Security screening and medical screening fail in structurally similar ways: even highly accurate tests produce floods of false positives at population scale, non-classification pathway effects may dominate, and the systems in which screening is embedded matter at least as much as the tests themselves. Those structural parallels suggest that the gap between test accuracy and system effectiveness is general, not domain-specific — and that understanding it requires theorizing about the mechanisms, not just improving the structure of the overall analysis.
That seems like a conversation worth having. Preferably before deploying the next generation of screening systems.
References
Malte Braitmaier, Bianca Kollhorst, Miriam Heinig, Ingo Langner, Jonas Czwikla, Franziska Heinze, Laura Buschmann, Heike Minnerup, Xabier García-Albéniz, Hans-Werner Hense, André Karch, Hajo Zeeb, Ulrike Haug & Vanessa Didelez (2022). “Effectiveness of mammography screening on breast cancer mortality — a study protocol for emulation of target trials using German health claims data.” Clinical Epidemiology 14:1293–1303.
Malte Braitmaier, Sarina Schwarz, Bianca Kollhorst, Carlo Senore, Vanessa Didelez & Ulrike Haug (2022). “Screening colonoscopy similarly prevented distal and proximal colorectal cancer: a prospective study among 55-69-year-olds.” Journal of Clinical Epidemiology 149:118–126.
Michael Bretthauer, Magnus Løberg, Paulina Wieszczy, Mette Kalager et al. for the NordICC Study Group (2022). “Effect of colonoscopy screening on risks of colorectal cancer and related death.” New England Journal of Medicine 387:1547–1556.
Bundesamt für Strahlenschutz (2025). “Mammography screening considerably reduces breast cancer mortality.” Press release, 9 July 2025.
A. Philip Dawid & Vanessa Didelez (2010). “Identifying the consequences of dynamic treatment strategies: a decision theoretic overview.” Statistics Surveys 4:184-231.
Vanessa Didelez (2008). “Graphical models for marked point processes based on local independence.” Journal of the Royal Statistical Society, Series B 70(1):245–264. (Preprint.)
Mette Kalager (2017). “Mammography screening — are we past the tipping point?” BMJ 359:j5625.
Mette Lise Lousdal, Timothy L. Lash, W. Dana Flanders, M. Alan Brookhart, Ivar Sønbø Kristiansen, Mette Kalager & Henrik Støvring (2020). “Negative controls to detect uncontrolled confounding in observational studies of mammographic screening comparing participants and non-participants.” International Journal of Epidemiology 49(3):1032–1042.
Tomer Meirson, Gal Markel & Daniel A. Goldstein (2024). “Survival outcomes of population-wide colonoscopy screening: reanalysis of the NordICC data.” BMC Gastroenterology 24:414.
Stephen Senn (2013). “Seven myths of randomisation in clinical trials.” Statistics in Medicine 32(7):1191–1204.
Mats Julius Stensrud, Jessica G. Young, Vanessa Didelez, James M. Robins & Miguel A. Hernán (2022). “Separable effects for causal inference in the presence of competing events.” JASA 117(537):175-183. (Preprint.)