


The Bear, the Biases, and the Bodies
Yet another post on epistemic humility


When the small boy (call him Christopher Robinson) wandered out of the bathroom holding the missing scruffy bear, it must be said that he looked more dumbfounded than overjoyed. Had the universe really given back his lovie? Could he keep it?
My immediate thought was that we had to take down the missing signs, a task for which I would not have time for a few days, and that this tardiness would make strangers passing by sad for no reason — a random act of emotional unkindness. (Sorry, if you happen to have seen one passing by the Kita and been so affected.)

But, as we readjusted to the proper homeostasis over the next few days, both of us kept just loving what we had more, since we had (thought we had) lost it. The boy, his bear, and me — watching him snuggle it with that extra warm glow generally associated with the oxytocin hit of holding the baby.
Presented with other toys, he would say, “I only want to snuggle something scruffy,” holding the beloved bear more tightly and inhaling whatever smell it held that I was not brave enough to experience for myself, it having been years since the creature had looked hardy enough for the washer.

Given a bear sugar cookie who closely resembled his bear, mailed from North Carolina by his doting grandmother during the chronic missing phase of his 1.5 week disappearance, the boy ate around the icing bear before calmly pronouncing “That’s enough sugar for now.” Twice.
Having hung my head and announced the bear had been lost on my watch (a first), related this to the danger and doom of doing better research in a world of misaligned incentives, and declared we should give up and get a new bear (an impossible feat given the irreplaceability of a lovie), I must now raise up my voice in praise of disused bathroom side cabinet drawers and their ability to contain the most precious of riches.
This is a reminder to be humble (life is a long series of reminders to be humble). And to be grateful (life is a long series of reminders to be grateful). And to think really hard about what you really know.
Yes, this is yet another post on epistemic humility.

How do we know what we need to know?
In the case of the missing bear, the outcome of interest was binary. The bear was absent; we wanted him to be present.
OR WAS IT????
You see my point.
Even the simplest of outcome variables can be clouded by perception. Even an apparently binary variable can be… Not.
This is one of the reasons why we need to keep it simple and try to count the bodies when it comes to risk assessment.
What does it mean to count the bodies?

The New Yorker features an excerpt from the updated fifteenth-anniversary edition of oncologist Siddhartha Mukherjee’s Pulitzer Prize-winning The Emperor of All Maladies: A Biography of Cancer (“The Catch in Catching Cancer Early: New blood tests promise to detect malignancies before they’ve spread. But proving that these tests actually improve outcomes remains a stubborn challenge,” June 23, 2025).
The update focuses on new blood tests for cancer that have the same problems as other mass screenings for low-prevalence problems (namely, rarity, uncertainty, and secondary screening harms). It’s usual for experts to focus on their field, and not on the broader class of problem, and that’s what the author does.
He hits the highlights: This structure of program implicates Bayes’ Rule, a theorem in the universal laws of probability that tells us how to incorporate what we already know. That means false positives (cases wrongly classified as problematic) will overwhelm true positives (real cases) in any mass screening for a rare problem. We must also be wary of lead-time bias and length-time (aka overdiagnosis) bias artificially inflating proxies like five-year survival. (See my review of Welch et al’s excellent Overdiagnosed.)
Mukherjee explains:
These twin illusions—lead-time bias and length-time bias—cast a flattering light on screening efforts. One stretches our measurement of survival by shifting the starting line; the other claims success by favoring tumors already predisposed to be less harmful. Together, they have misled cancer researchers for decades.
Nonetheless, researchers tend to use bad metrics because it is so much harder to use better ones. It takes a lot more time (decades) to see if people actually live longer with screening than without. It takes a lot more money to keep following them out. And, in contrast to the people who make money from the screenings and follow-ups, the people who benefit from spending that time and money (the patients, the public, society) don’t necessarily know they benefit from it, or appreciate the benefit that knowing the truth would afford them.
“My mom’s life wasn’t saved by not screening, but at least she didn’t live with chronic pain for years from surgery and radiation therapies for a tumor that overwhelmingly likely would’ve gone on to be clinically insignificant” — can’t compete with “Mammograms save lives” on a sign.
Correction
Mukherjee denies the uncertainty that remains even about the net mortality efficacy of colorectal cancer screening, which I wrote about here. He appears to fall prey to statistical significance testing misuse in representing trial outcome data as showing certainty instead of the uncertainty they actually embody. As such, he misstates that a trial on over 84,000 people in Poland, Norway, and Sweden (the NordICC trial) published results in NEJM in 2022 showing “an estimated fifty-per-cent reduction in deaths associated with colorectal cancer among those who received colonoscopies. Every four to five hundred colonoscopies prevented a case of colorectal cancer. The benefit was real.”
This is wrong. In reality, as John Mandrola and Vinay Prasad wrote at Sensible Medicine, the trial showed a modest possible, not certain, mortality benefit from colonoscopy screening invitation (“Screening Colonoscopy Misses the Mark in its First Real Test,” 2022).
Mukherjee missed that counting the bodies still involves uncertainty. A correction based on the NordICC trial data would read:
The screening had no certain effect on all-cause mortality. The trial evidence is consistent with an up to 4% reduction to an up to 4% increase in overall deaths (95% CI .96-1.04). No survival benefit was proven. It is also uncertain whether the screening reduces colorectal cancer deaths. The trial data are consistent with an up to 36% reduction or up to 16% increase (95% CI .64-1.16). In absolute terms, the observed difference was 3 fewer deaths per 10,000 people, but this difference may be due to chance. (Here Mukherjee also erred in giving the relative risk when people need to also or instead know the absolute risk of a rare event in order to make sense of it.) Every 270-1429 invitations could prevent one case of colorectal cancer (95% CI 270-1429).
It’s not as much fun to write or to read, and it doesn’t tell you what to tell your mother about the screening. Should she get it? Should she not? Probably the answer depends, as usual, on context. Does she have risk factors? How long could she have left? How much discomfort is it worth, to try to extend what quality of life by how much?
Counting the bodies is hard and thankless work
Even a world leading oncologist and science writer can get this stuff wrong in The New Yorker. Wrong is the norm. Why?
It’s harder to get right published. People don’t like it as much. It rubs us the wrong way. We want to know stuff. Stuff that is generally hard to really know. Dichotomania and all.
We also want to know what to do. Post a sign? Buy a new bear? Watchful waiting is no fun. It feels like you should be doing something.
But only time will tell who will still be alive in 20 years. Or whether Christopher Robinson has stuck Papa Bear in a disused drawer, somewhere you wouldn’t have thought a Papa-sized bear could fit.
How does counting the bodies generalize?
We find this structure of program — mass screenings for low-prevalence problems, a subset of mass preventive interventions for low-prevalence problems, a subset of mass interventions, a subset of legal regimes — across domains, but that’s usually not recognized. We’re doing pretty well when we recognize the false positive problem. And we’re doing great if we also recognize that there are causal pathways beyond test classification that these sorts of programs can work along — namely, strategic behavior, information effects, and resource (re)allocation. Most efficacy analyses just look at the classification pathway and treat that as showing net effects, when that’s especially wrong for security programs of this structure; deterrence and elicitation, for instance, could work to make polygraph programs net save lives in security agencies.
So counting bodies isn’t easy, it’s not as binary as it sounds, and we still have to attend to causality and uncertainty (as in the rest of science). But it is the most basic thing we should be doing to assess program efficacy. That looks like taking the time and expense to measure all-cause mortality in cancer screenings, and communicating that information accurately to people deciding whether to consent to those screenings. From mammography to colorectal cancer screenings, the reality keeps falling far from the aspiration here. What does this look like in other contexts?
One obvious generalization in current discourse is to the debate on vaccine outcomes, and whether antibody titers are good proxies. Spoiler alert: there are only bad proxies.
Ok, that’s trite. The beautiful thing about vaccines as a case study of is not that antibody titer proxies represent a bad proxy I can pick on. It’s how they demonstrate the difficulty of picking the right endpoint. Or, more accurately, how much uncertainty and ambiguity there is to sort through in selecting endpoints. How much gets packed in as known, when there’s a lot of unknown…
An endpoints rainbow
For cancer screening, we know the number of cases diagnosed is a bad metric for whether a screening works because of overdiagnosis bias, five-year survival is a bad metric because of lead-time bias, and all-cause mortality is a better metric because it tells us what we want to know — if the screening saves lives. But it tells us that net, and we might want patient-specific info instead (e.g., does the screening make sense given risk factors?). And it doesn’t compare prevention to screening, when as a society we might want to know what that calculation looks like, in a world where we want to allocate limited resources wisely to save the most lives.
For vaccines, similarly, antibody titers arguably present a bad metric for whether a vaccine works because vaccines are like drugs, come with possible harms as well as benefits, and so we need to see net effect estimates. Drug companies have perverse incentives to produce antibody titer estimates instead, because they’re quicker, easier, and less likely to show rare harms. Although, if you know the number needed to treat is quite high but so is the disease’s body count, it might make sense to satisfice and get the shot — even if there are safety concerns about the vaccine and no one is handing you an info sheet with the risks and benefits tallied up (as with child meningococcal vaccination). It’s a judgment call.
So is what endpoint to look at in the first place. Vaccines for highly communicable diseases like measles implicate equilibrium effects: if enough people vaccinate, the disease isn’t endemic and society benefits from herd immunity.
That’s a different endpoint from serious/severe infection risk, hospitalization risk, disability risk, death risk from or with the specific infection, and all-cause mortality. Live vaccines — like, ironically, the measles and the rest in the MMR shot that Wakefield fraudulently fingered as a cause of autism — may confer more general immune advantages. Their non-specific effects may include lower death risk from infections in general, not just from the infections against which they confer immunity. They may actually make people’s immune systems work better — especially females, which may be especially valuable information for girls and women with autoimmune disorders that predispose them to frequent infections.
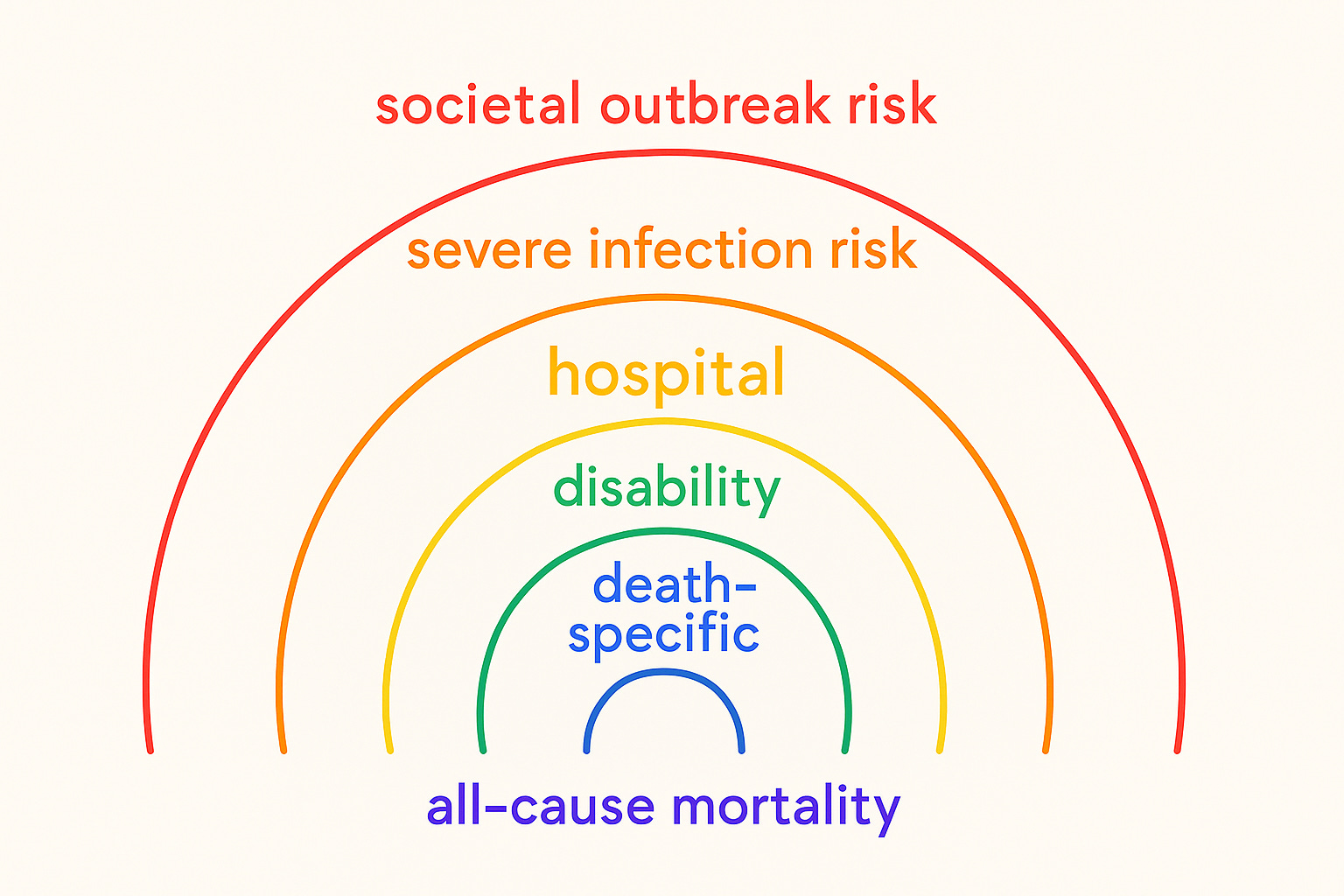
We care about all these endpoints. We want to see the whole rainbow. We want to be explicit about the uncertainty and possible harm/benefit in terms of each metric. And we’re not getting this information in normal efficacy analyses, much less clinical encounters.
What does this look like in security and other rule-abidingness screenings?
Does all-cause mortality translate from cancer screenings and vaccines to all-cause mortality in mass security screenings for low-prevalence problems, like border screenings and mass telecom surveillance, or other rule-abidingness screenings like those for fraud in welfare benefits administration and integrity in scientific publishing? Probably not.
The best case for generalizability comes in the security issue area, where we do arguably want to know if security screenings save lives. The problem is that different people might value different lives differently. For instance, while I have argued that next-generation lie detection should not be used to screen climate refugees due to the false positive problem, others might argue that, in a world of scarcity and crisis, it makes sense to do that — assessing whether such a program could net save lives in the society of refuge, and discounting lives lost due to false positives.
More realistically, security screenings (like other mass interventions) don’t usually come with real-world efficacy data or the infrastructure to produce it, much less to share it transparently. So we wind up looking at proxies like how polygraph programs affect police brutality (they may decrease it), when what we really care about at a national level is whether these programs detect or deter spies in national labs.
I know, it’s weird that I just keep staring at this table (the seminal portion of Fienberg’s 2003 NAS report on polygraphs and lie detection):

But I have to wonder now, and then wonder why I’m wondering now for the first time: Is this even the right endpoint?
It is not. It is a proxy. At best, one color in the rainbow.
So what’s the right endpoint for efficacy studies of mass security screenings for low-prevalence problems? Or the right endpoint rainbow? Or the closest attainable thing that we would still have valid reasons to care about as scientists trying to figure something out in the public interest?
Find that bear
There’s an old saw: don’t look for your keys under the lamppost — you look where you lost them. But that most researchers look under the lamppost anyway, “because that’s where the light is.”
I must admit I posted the bear signs where there were lampposts, although that was also where I figured he must have been dropped last Tuesday in the rain.
But at least I was looking for the bear, and knew when he had been found.
If we don’t specify the right endpoints, or we specify the wrong ones… If we don’t take the time (and spend the money) to count the bodies… If we don’t have the humility to admit we might not understand all the causal pathways in play… Then we’re gambling.
Gambling with the credibility of science, government, experts. Gambling with public trust. And gambling with lives. Risking massive societal damages from mass screenings (and preventive interventions, interventions, and laws).
So let’s remember the bear — what’s really our goal? The biases — what’s likely to throw us off course? And the bodies — what do we really need to count?
So Scruffy Bear was in your own bathroom drawer all along? That's a funny, happy ending. :)