
Bad Proxies Are Bad
Friends don't let friends measure what's easy instead of what matters -- but what matters is open to interpretation.


Papa Bear went missing again, this time for one week and six hours. Christopher Robinson had just decided that he must have gone to Decathlon, an immense sporting goods store almost as far away as America (25 minutes walking to downtown Berlin), where he was looking for a right-sized bike. Or a family-sized tent for camping. Or the nearby Häagen-Dazs where we make an annual Belgium Chocolate Chocolate pilgrimage.
When he reappeared at last, it was in the middle of the fourth attempted tucking-in of the resident little sister, when Christopher Robinson had been instructed by the closed door to stay away, since he could not by any means or for any ends be quiet and still — but then called in a voice so winsome “Mom, come see what I found!” that it could not be ignored.
Such joy comes but a few times in life — at least until the little boy loses his precious scruffy bear twice in a fortnight, and then it comes twice in a fortnight, when the lost bear reappears once more in the apartment (as suspected), looking scruffier and more irreplaceable than ever, as if returned from Narnia with a new (old) glow. I must admit that I held and kissed the boy, then the bear, then the boy, then the bear — although normally I leave the bear his microbiome, which scientists tell me is unique. And then I wondered what else had been stuffed in a pillowcase (already full with a sofa pillow), and still remained to be missed or rediscovered.
The usual nerdiness ensues
Now what does this have to do with science in general, and mass screenings for low-prevalence problems (my lovie) in particular?
This post is about the trouble with proxy endpoints — and with figuring out how to better measure what we really care about instead of what’s easy (enough) to measure. Bad proxies pervade science both because we are not smart enough to stamp them out (being stupid monkeys), and because perverse incentives favor them.
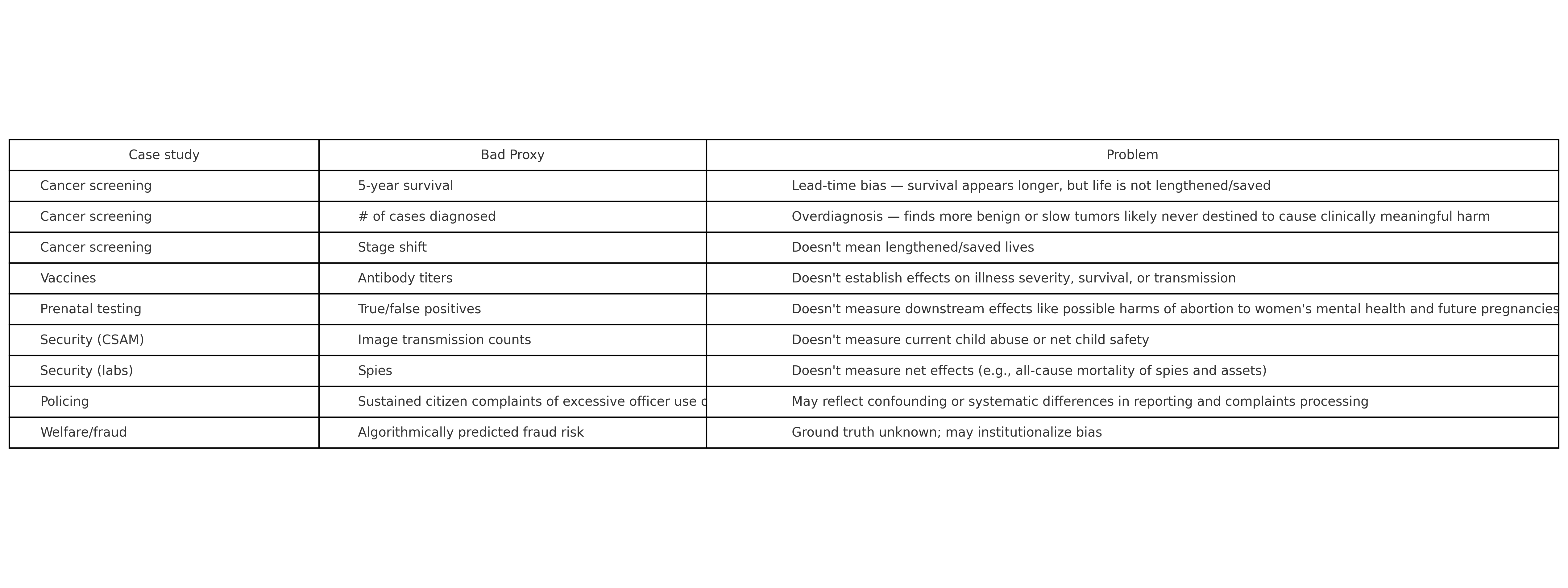
(Table made in o3.)
For instance, five-year survival or number of cases diagnosed in oncology can make oncologists look like miracle workers for charging for more screenings and treatments even though they don’t change all-cause mortality. That is, lives may or may not be saved overall, but the evidence is inconclusive on this point. The money a whole industry makes from associated interventions, meanwhile, is real.
Similarly, vaccine studies evaluating antibody titers instead of disease outcomes (e.g., Covid-related hospitalization or death) favor the companies funding such trials, because they’re much faster and cheaper to run, and more likely to seem to show a benefit likely to help the companies sell more vaccines. Why would a company run a tougher, more expensive test, unless a scientific norm and/or public institution made it?
So we could call bad proxies scams, but it’s slightly more politic to call them part of the spin science ecosystem. It’s also more accurate, because doing spin science doesn’t require bad intent.
It may be more controversial, but I think we should call CSAM (“child sexual abuse material”) transmission a bad proxy for child welfare/safety/present child abuse. What we really care about is the latter (human beings, not images). And it’s not clear that policing CSAM transmission from the bottom up through mass surveillance will meaningfully impact the thing we really care about here, child safety. Now I wonder if this is what Signal CEO Meredith Whitaker was getting at in her criticism of the base rate bias criticism of these sorts of programs.
Point being, sometimes proxies are useful in science in the public interest, as when we want a quick answer about whether a new vaccine might be effective against a new disease. Sometimes they’re useful in science in corporate interests, and those interests differ from the public interest — but the institutions that are supposed to protect the public against corruption can be captured or influenced by those same corporations. Sometimes they make bad science, as when lead-time and overdiagnosis biases make cancer screenings/treatments appear to “work” when they don’t really lengthen or save lives. And always, they shape the way we think about what works by setting the terms of the discourse.
This is clearest in the example of Chat Control, the EU’s proposal to AI-scan all digital communications for CSAM. Here, criticizing the endpoint can be misrepresented as an argument that we don’t want to stamp out CSAM. Of course we do. But doing that is not actually the same thing as making children safer in real life, and we shouldn’t confuse the two.
(Or is it? We could test this: One could envision a randomized trial in which one country or set of countries implements Chat Control-like scanning and another country or set of countries doesn’t, and researchers specialized in collecting sensitive information run representative surveys of kids and teens to assess their safety and well-being in both countries/sets of countries. Proponents should want to do this if they really think the program will affect that endpoint. So why has no one has proposed this publicly? It could presumably be done among countries that have already agreed to support the program. Why not pilot first and extend to other countries later? My guess is it’s a lot less work and strategically lower-cost to just keep proposing the program than to structure an efficacy test that it could fail. Critics would presumably still oppose such a test, because primarily they seem concerned that the surveillance infrastructure would be abused to target political dissidents despite transparent judicial processes that would seem to prevent straight-up framing, and that mass surveillance could have chilling effects on free speech for related reasons.)
What if what I thought I knew about good endpoints was wrong?
Whether the bear is lost or found is a binary variable. But whether the bear is in the apartment or not is a different binary variable. And whether we know he’s in the apartment for absolute certain, or merely strongly suspected, it is another.
When you think about this long enough, and with enough sadness in your heart for the boy who again (reunited the first time, as the second) kept exclaiming “I just want to snuggle something scruffy!” and hugging his lovie tight, it begins to seem paramount that you don’t just need to know if the scruffy bear IS or IS NOT with us after all. You also need to know something about the quality of your BEING-WITH the scruffy bear. It’s the possibility of the snuggle that counts.
Not to go all Heideggerian — I haven’t been living in Germany that long, only Berlin — but you need to be linked to your bear in daily life, even when he’s in another room, through shared social practices. You may be getting dressed on the tenth try under threat of a time-out, for example, but be busily thinking meanwhile of which bowtie to put on Papa Bear, where he’s going with Ursa (his sister, or his grandmother, or the big koala bear Allie’s husband, “depending on the context”), and whether they’re taking Fox-in-Socks — that’s what makes you happy and distracted, which is to say, your normal self.
From scruffy bears to breast cancers
A fresh example: The UK NSC (National Screening Committee) recently hosted a seminar on breast screening and density featuring a presentation by Committee member and radiologist Dr. Rosalind Given-Wilson, who set up the breast screening service at St Georges Healthcare NHS Foundation Trust in 1991 and was Director of Screening (a history which reflects and incentivizes screening support). Given-Wilson’s presentation frames mammogram screening for early breast cancer detection as net benefitting women, stating “Evidence from large trials shows a 20% reduction in risk of dying.”
This is wrong. Mammography confers no established net mortality benefit. The mistake reflects the predicted direction of bias.
The nicer way of saying this is that the central framing claim is contested, may confuse breast cancer-specific with all-cause mortality, ignores uncertainty in available estimates, presents a relative risk reduction in the absence of important contextualizing information about absolute risk, and omits counterbalancing information about harms.
The gold standard of risk literacy doing most of that looks like this, though it could better recognize uncertainty like this.
This is why I love breast cancer screening as an example of mass screenings for low-prevalence problems: Mammography is particularly well-studied, the correct evidentiary standards are generally agreed, and even so, we don’t have evidence establishing net benefit — and leading experts don’t abide by the widely accepted evidentiary standards.
If they did that, they might be out of jobs, be responsible for net harm, and be seen as people who had profited from preying on others’ anxieties and frailties instead of experts who had served the public interest.
It should always be said that there’s no malice required for intelligent people to interpret complex, ambiguous evidence in ways that happen to benefit them or protect their interests (psychosocial, professional, financial, and otherwise).
So what if you can’t prove mammography works but can’t kill the programs (what are you, Team Cancer?) or convince the experts to play by the rules (just say we don’t know if they save lives or not)? This being one of the best-studied medical interventions ever, and sharing an identical mathematical structure with a growing number of other programs — mass screenings for low-prevalence problems — then that suggests that other programs in this class are probably more doomed to uncertainty about their efficacy. And that we’re probably doomed to scientific and popular discourse about them dominated by ignorance and guild interests. Woe is us.
But let’s try to make some sense of this mess anyway.
Life versus quality of life
Yesterday, a lovely person and friend who, at just four years north of my deniable forty, is a breast cancer survivor, relayed a fight with a doctor over endpoints. She wanted to be monitored every three months for recurrence. Her gyn does it with ultrasound.
A radiologist told her it doesn’t matter, to just get the yearly mammo and relax. That more screening would only make her more anxious, and not change all-cause mortality. The “hard” endpoints generally considered gold-standard in oncology are length of life (do you live longer?) and all-cause mortality (do you die less?).
My friend responded that catching a recurrence earlier could allow for gentler treatment, possibly avoiding chemo — and resultant higher quality of life with her remaining time. More of her would be present during that time to spend it with her family, even if the life-and-death outcome didn’t change.
We rolled our eyes together at the idea that a cancer survivor would be made more anxious by more monitoring. Some people have no empathy as well as no Bayesian statistical intuition.
I related to her quality of life concern as a lupus patient who relies on steroids to function. If they cause problems later, I’ll burn that bridge when I come to it — I just want to be able to move and think with the life that I have.
And I moaned about science and Bayesian updating, and how the incentives are all wrong for researchers to actually do the subgroup analyses people need done to assess their own risks (e.g., less versus more frequent cancer rescreening by cancer subtype and stage) — much less translate their results into user-friendly formats (e.g., relating life-and-death and quality of life endpoints in usable metrics). It would be a huge scientific and technological undertaking to fix this with some sort of infrastructure to do the work that should be done as a matter of course, but isn’t. The incentives are sadly wrong for someone to take it on.
More to the scholarly point, the lived insight about the primacy of quality of life conflicts with my empiricist prior here — with the idea that we should be focused on counting the bodies. What if even net all-cause mortality in oncology — a gold-standard endpoint that matters — is an over-simplification that often does a disservice to patients in their decision-making? And what if Stephen Fienberg and the National Academy of Sciences go this part wrong in their seminal polygraph report, too?
A third polygraph report bug?
For those keeping score, this is three of three core methodological criticisms of Fienberg’s NAS polygraph report, the list so far being:
overconfidence bias in asserting a known net security program cost after calculating effects from only one causal pathway among four (so net effect actually remained unknown),
applying Bayes’ Rule in a one-off when some other flavor of Bayesian statistical analysis accounting for test iterativity (e.g., multilevel modeling) might make more sense in this and other mass screenings for low-prevalence problems, especially when we get into other mass security screenings like telecom surveillance (e.g., Chat Control), and
assuming spies in labs was the endpoint of interest, when maybe something else was.
I don’t know what the right endpoint is in most security screening programs, but I know we probably can’t measure it. Uncertainty surrounding the ground truth of stuff people have huge incentives to lie about comes with the issue area territory.
That was Fienberg’s point in highlighting the intractability of the validation problem in the context of polygraph programs:
I don’t know what’s the experiment I could conduct that’s double-blind that would give me enough data to conclude that this works or it doesn’t work, and I don’t know how to plan for it, and I’m not hearing any of these people saying that they’re worrying about that. They’re using it in some trial program, but I can’t imagine they’re using it in the context where I want to see it evaluated, and I find that pretty frightening. - 2009 interview
The issue is that we can’t measure ground truth in a lot of security contexts like we can in oncology. You can get data on causes of death from autopsies. You can’t get data on espionage or child sexual abuse like that. The base rate is unknowable. You can’t get field data on “lie detection” under realistic conditions, because the whole problem is that you don’t know when people are lying about stuff that really matters, in the first place.
Moreover, the diseases in these cases are quite heterogeneous. They’re analogous to cancer cases, not all-cause mortality. Looking at cancer cases can lead us astray due to lead-time bias (catching cancers sooner without lengthening survival in the end) or length-time/overdiagnosis bias (catching cancers not destined to kill people anyway). We can avoid that, and account for possible clinically important treatment harms, by eschewing proxies like five-year survival in favor of estimating all-cause mortality effects.
(However, it should also be acknowledged that this kind of accounting fails to consider quality of life, which may matter a lot. Chronic pain, for instance, may be very common after breast surgery. Chronic anxiety/medicalization may also matter a lot to some people. So even counting the lives is debatable as a choice of endpoint. But at least we can generally agree that we really care about saving lives.)
That’s why the world-leading UK National Screening Committee looks for high-quality evidence from randomized trials that a program reduces mortality or morbidity before recommending it. They also want evidence that the program causes more benefit than harm at reasonable cost, though their recommendations don’t always adhere to that standard. See, e.g., conflict of interest and failure to apply that standard in recent NHS assessment of abdominal aortic aneurysm screening. And conflict of interest and failure to apply that standard in the recent mammography/breast density seminar (see above).
So where does that leave us?
Endpoints — are they all proxies?
Yes. All endpoints are proxies for understanding the underlying causal generative process that created them. We don’t just want to know the what (or how much); we want to know the why.
Bodies are generally good proxies. They are still proxies, though. In the cancer survivor rescreening anecdote, all-cause mortality is a proxy for length of life where we care about quality of time left to spend with your family.
(I’m just going to pause in the helpless, dumbfounded realization that even all-cause mortality in oncology is a proxy, and not necessarily a good one, depending on the context. Where is up?)
At least we know that many other proxies are worse. So can we count the bodies in other contexts, or are we stuck with worse proxies — and how can we make them better?
Endpoints — does all-cause mortality generalize?
No. And this is a problem for understanding how to even theoretically agree on what works and what doesn’t work (or backfires), given relatively complete information we’re not likely to have or be able to get in any given case.
In general, we care most about life-or-death outcomes. Whether other stuff is practically important is more or less debatable, but whether people live or die is not. Even so, we can’t agree that all-cause mortality is what we care about most for most programs of this structure… Complexity and ambiguity pervade.
Medical example 1, vaccines (mass preventive interventions for low-prevalence problems): Companies like to measure antibody titers because that’s quick and easy, and thus cheaper than measuring what we arguably care about as a society…
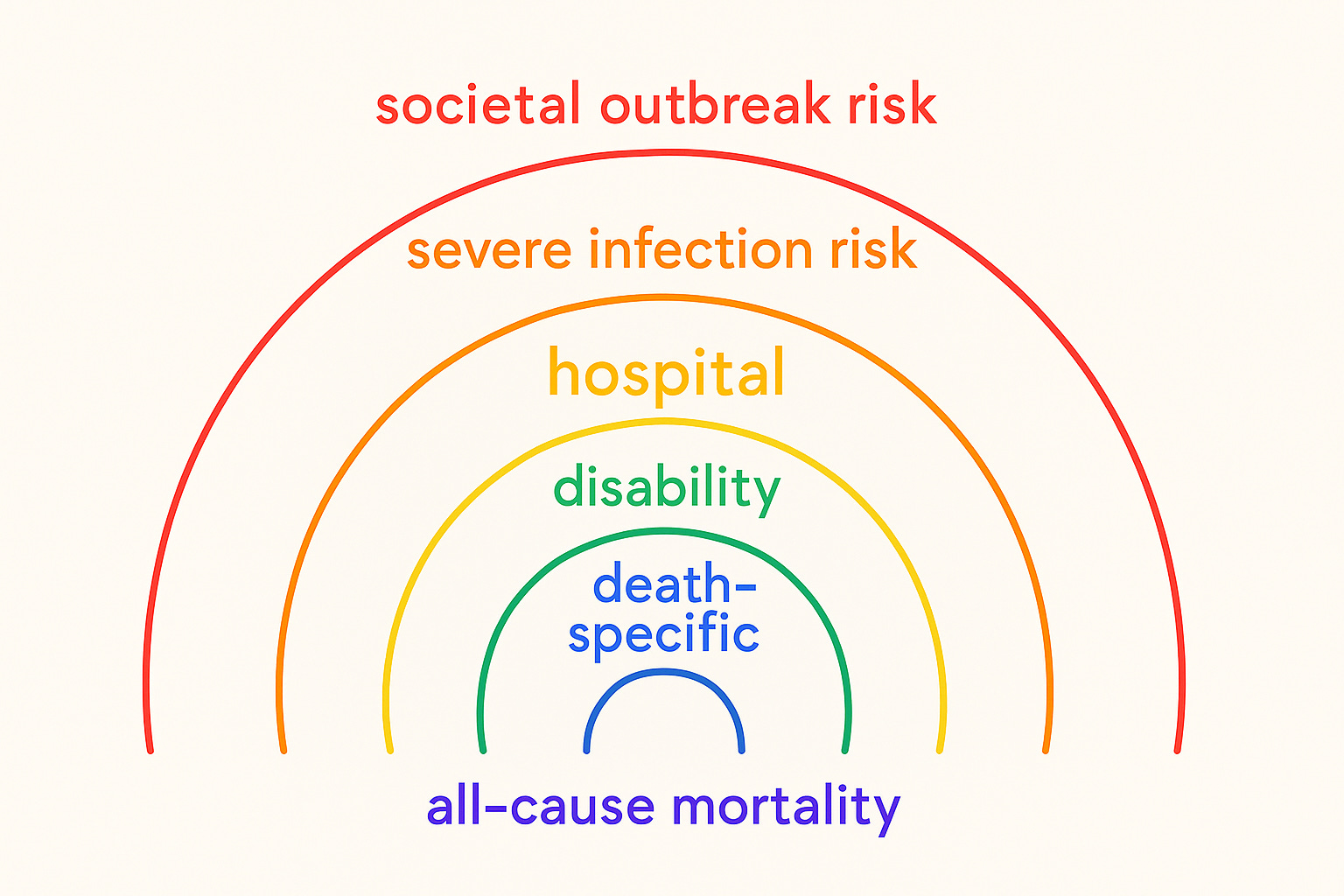
Medical example 2, non-invasive prenatal testing (mass screenings for low-prevalence problems): Risk communication typically focuses on the test classification alone, calculating stats for true/false positive/negative endpoints without going further downstream to spell out the possible risks of resultant abortion for women’s health and future pregnancies.
Security example 1, polygraph programs for spies in national labs: What if some level of spying among friends (or enemies, or frenemies) is an international norm, and it’s not the spying that kills people in this complex system with equilibrium effects, it’s something else? If I were an intelligence agency, I would expect spies to spy and try to minimize preventable deaths from a particular subtype of spy, just like if I were an oncologist, I would expect some cancers to con the immune system enough to grow enough to be diagnosable without being clinically important, and try to minimize preventable deaths from a particular subtype of cancer. In this analogy, the NAS polygraph report’s endpoint was wrong.
Security example 1.5, Project Equalizer: What if a 1980s Chaos Computer Club fringe group collaborated with the Russians, because they worried the Americans were dominating and that would throw the international system out of balance, resulting in nuclear Armageddon? Just to illustrate that equilibrium effects themselves don’t even have to be real in the sense of proven ground truth to be perceived and drive important behavior in the international system.
Security example 2, mass digital telecom surveillance for CSAM in the EU’s proposed “Chat Control”: What would a body count look like here? Do we care about materials relating to live abuse cases or historical ones, or both but to differing degrees? Police are just there to enforce the law and all CSAM breaks the law. But it doesn’t seem like one more transmission of illegal images that you can’t get off the Internet once they’re out there anyway (sorry) is equivalent in sociopolitical/child welfare importance to one more child being abused. And if what we really want is to minimize children who are being harmed in the real world at the present time, it’s not clear how to count that to assess program efficacy. (Or rather, I have some ideas, but no one is going to implement them because Chat Control proponents have no incentive to run a study that could suggest their program doesn’t work or actually causes net harm to kids, while critics would oppose such a study because it could prove the program is workable with safeguards against feared abuses and data on feared chilling effects.)
Proxies dominate
due to ambiguity and complexity in assessing quality of life in combination with net mortality in oncology and other medical contexts, and ambiguity/complexity plus secrecy and the intractable validation problem in security contexts.
We want to find that bear. We want to pick endpoints in science that actually matter to people in terms of making their lives/society meaningfully better.
Maybe we can’t have good endpoints, only less bad ones. Unless we are making qualitative and quantitative multi-method 30-year book project works of art (call me, Simon & Schuster), we probably can’t consider everything that we would want to consider to help a friend with a relevant decision. There’s probably too much remaining unknown in the crappy existing scientific evidentiary basis for those decisions, anyway.
So bad proxies are bad, but we are stuck with them? Meh.
How to make inevitable proxies less bad
Look for bias and error. One classic bias in mass screenings for low-prevalence problems is the base rate bias, even though correcting for it doesn’t give us net program effects, after all. One typical source of error in all human endeavor is misaligned incentives, with motivated reasoning generally understood to pave the way for cognitive distortions to stay, well, distorting.
I don’t know what a good endpoint that we can actually measure would look like in mass security screenings. But we can’t be agnostic to their sociopolitical effects as scientists, just because it’s difficult to formulate better studies than the ones we’ve got. Lives are at stake, public trust is in play, and sometimes proxies present themselves in available data that are not so bad.
For example, maybe acknowledged police brutality was not such a bad proxy for estimating the possible effects of police polygraph programs. I wouldn’t claim we know the programs’ effects from my dissertation difference-in-differences analyses, but I also wouldn’t claim there’s no evidence the programs may work to do exactly what they’re supposed to do, make better police forces. And that possible effect could generalize to other security contexts.
So I’m wondering if there are decent real-world crime data proxies for child sexual abuse prevalence that could be measured or simulated in relation to a Chat Control-like surveillance program. That would be better than measuring cases of CSAM transmission caught in the net, I think. We can’t directly measure how safe or unsafe children are in the way we really want to. But if the point of such a program is to make them safer, we had better at least think about trying.