
These Are A Few of My Favorite Things
That DAGs don't do: feedbacks, bias, private information, perverse incentives, moderation, and telling you where to cut the graph


When my son was a baby, his father built him the most amazing present: a rail with a harness so that he could walk up and down in our office before he could walk, even in a walker. The custom-built contraption gave him support to stretch his legs and exercise his freedom, literally, before anything else could.
Not having any idea what a very lucky baby he was, after a brief cry of joy at meeting his new toy, our son immediately protested. The problem? He wanted to walk everywhere in the room. Not just in a straight line along the rail. But wherever he wanted. As was obviously his right. The injustice!
The same righteous indignation wells up in me now regarding directed acyclic graphs (DAGs). We are very lucky babies to have this logical rail to structure better science. We basically can’t walk (i.e., do good science by first thinking logically about causation) without this aid. But we also can’t go everywhere in the room with it.
Here are six places DAGs don’t go. Or at least, not easily. These are recurring structures in complex systems that often break DAGs’ assumptions, or require extensions beyond them…
Feedback loops, which implicate equilibrium effects, which break DAGs.
Bias in real life, where feedback exists.
Private information constraints, which involve feedback.
Perverse incentives, a private information problem.
Moderating effects.
Indeterminacy — telling you where to cut the graph.
Feedbacks / equilibrium effects
Pretty obvious, when you spell it out — directed acyclic graphs don’t do cycles. (DCGs, directed cyclic graphs, do that.)
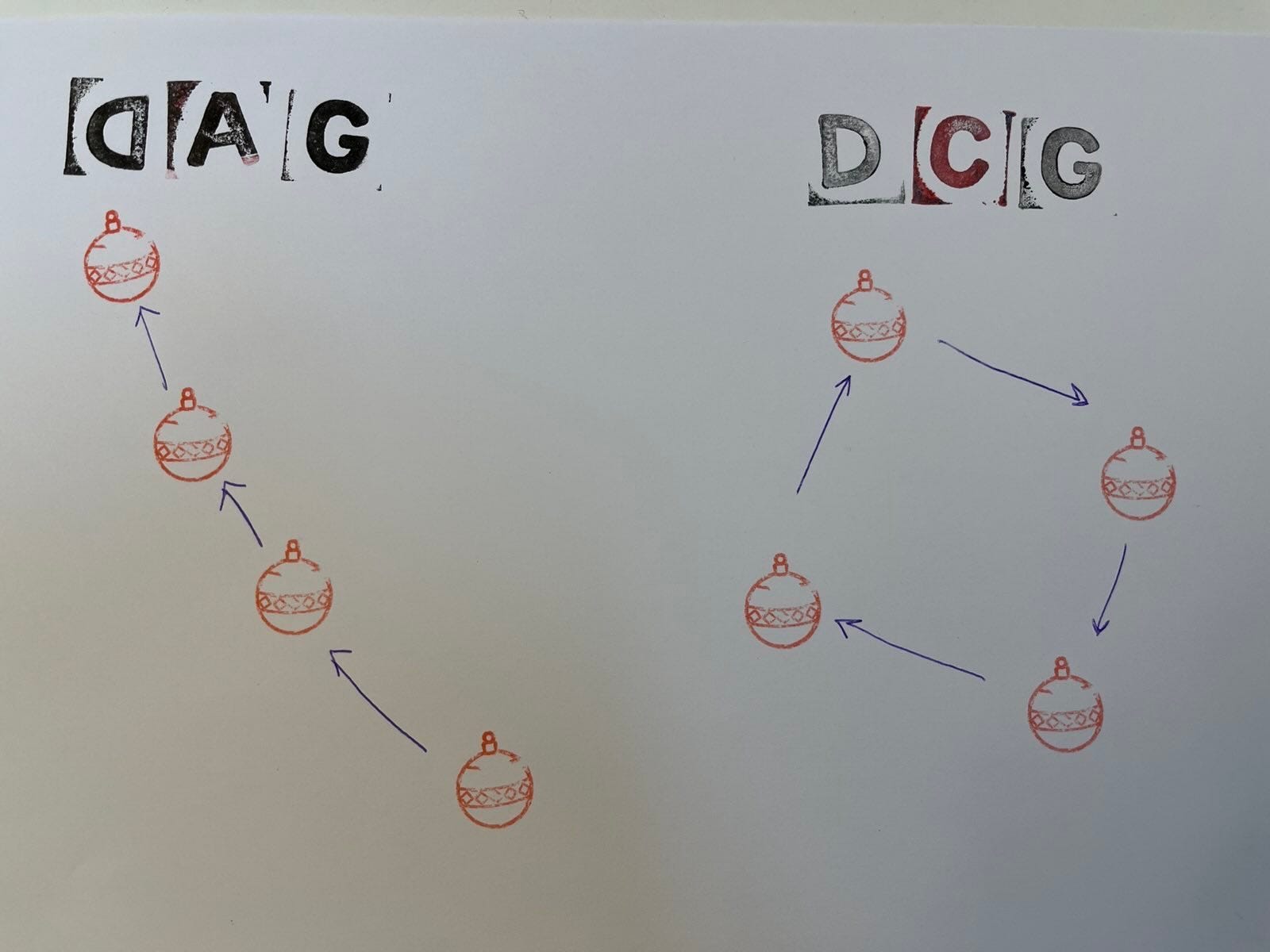
So feedbacks are out of the picture. Which is a pity, since that’s basically all human behavior.
Feedback implicates equilibrium effects. Equilibrium effects are everywhere, from measles vaccination to dating, markets, and law enforcement. Whenever we’re thinking about strategic behavior or information effects, we’re thinking about feedbacks. (I glossed some recent readings on equilibrium effects in the last post.)
But wait, why don’t DAGs do feedbacks if you just write a series of them (e.g., T0, T1, T2…)? Isn’t it just a matter of slicing time to make them play nicely?
No. Time-indexed DAGs represent delayed effects and some forms of state dependence. But they still assume acyclicity (just across time slices). So they can't represent true feedback loops in which A affects B and B also affects A in the same time frame. Mutual causation or recursive updating characterize true feedbacks. Time-indexing preserves acyclicity and thus misses equilibrium effects.
Take, for example, polygraphs: Even in a one-off, test-mechanism-only polygraph, if the subject’s belief about how well the test works affects the test, that circular dependency necessitates recognition of cyclicity in the graph. (So polygraphs require DCGs instead of DAGs.)
The difference is illustrated below (Figure 1, Ragib Ahsan, David Arbour, and Elena Zheleva’s “Relational Causal Models with Cycles: Representation and Reasoning,” Proceedings of Machine Learning Research, Vol. 140:1–18, 2022, 1st Conference on Causal Learning and Reasoning).
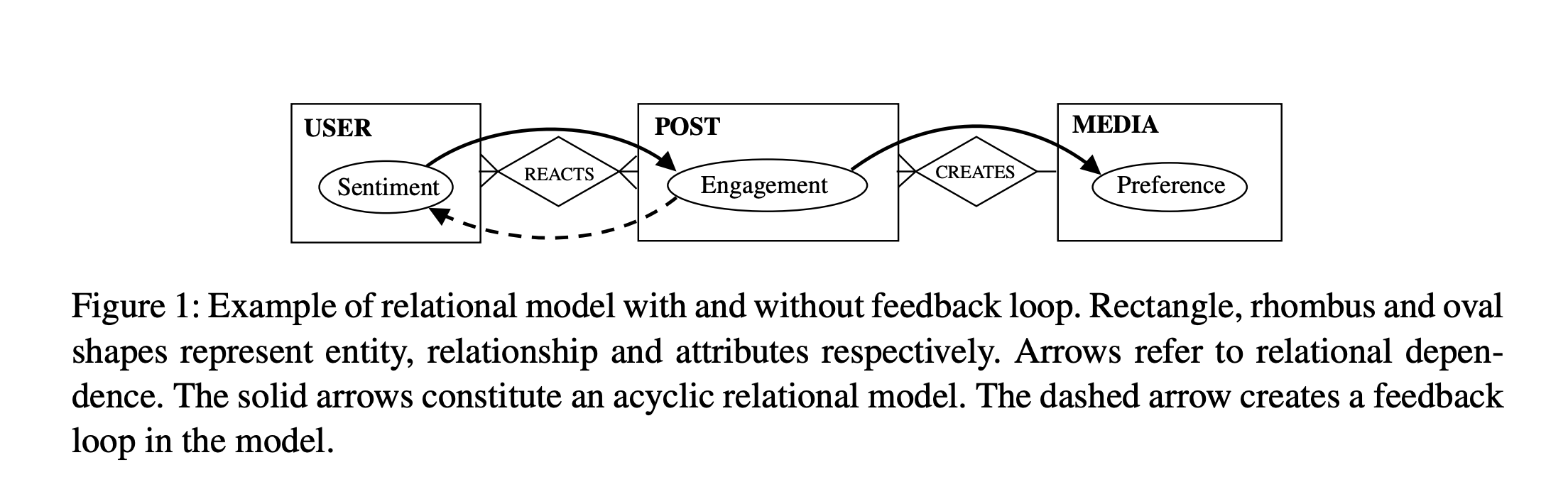
The operative point is that feedback loops are really different structures from causal processes that you can slice up into sequential DAGs. Equilibrium effects, especially those involving strategic behavior, belief updating, or dynamic deterrence, often involve mutual causation or cyclic dependence. That’s fundamentally outside what DAGs can depict, even with time slices.
So DAGs can’t depict the continuous, recursive, or mutually adaptive dynamics we see in real-world complex systems where effects are not just sequential but interactive. Expanding DAGs in time helps with some lags, but not with full-blown feedbacks.
Bias in real life, where feedback exists
Bias can affect every causal mechanism. This may complicate experimental bias research to the point of practical impossibility. I say this as a scientist who did NSF-funded PhD bias research involving lots of experiments. I was asking the wrong questions in the wrong way, and so my project was doomed to fail. Oops.
It gets better: There are multiple reasons why most NSF-funded bias research is similarly doomed to fail. The incompatibility problem of statistical fairness criteria is one. The implications of the causal revolution are another…
If I thought it was hard collecting some data to look at interpreter bias, subject bias, and their interaction for my dissertation, just imagine how basically pointless it would be to try to collect that data along four different causal pathways. That would involve a 4x3 matrix for just one binary bias variable — be it ascriptive, cognitive, measurement, or selection bias. Forget about any interactions like those between racial and confirmation bias that my dissertation set out to focus on. Especially forget about feedbacks.
That’s exactly what some cutting-edge causal literature does. A few of my favorite bias articles building on the causal revolution are:
“Causal Foundations of Bias, Disparity and Fairness,” Traag and Waltman, 2022; and
“Administrative Records Mask Racially Biased Policing,” Dean Knox, Will Lowe, and Jonathan Mummolo, 2020.
Both papers offer rigorous and thoughtful contributions to bias research through a cutting-edge causal lens. (They were flagged as exemplary in “Statistical Rethinking” when I audited part of it before getting sick a few years ago.)
But they largely treat causality as a unidirectional chain, since that’s what DAGs let us do. This works well when isolating specific pieces of the puzzle, like estimating racial disparities in use-of-force conditional on encounters already having occurred. Knox et al’s identification strategy is careful, and their contribution is important.
Yet, as they themselves acknowledge, it’s only getting at one slice of a much larger, dynamic system:
“The data we have pick up halfway through the encounter, after officer bias very likely has already exerted an effect,” said Mummolo, a professor at Princeton. And without knowing the racial composition of the people who are sighted by police but aren’t stopped, it’s impossible to fully correct for the bias. The paper provides a suggestion for how to estimate bias in one part of the chain — use of force in encounters — but it doesn’t capture any of the potential disparities that occur beforehand that make the encounter likelier…
“We need to think about this as this complex system,” said Knox. There are biases layered on biases — social decisions like how society allocates resources in education versus policing, and individual decisions like who police choose to stop or arrest and who is ultimately charged or convicted. ‘It just compounds all the way down the line,’ Knox said. — “Why Statistics Don’t Capture The Full Extent Of The Systemic Bias In Policing,” Laura Bronner, FiveThirtyEight.com, June 25, 2020.
Similarly in Traag and Waltman, there’s a wealth of insightful analysis of how diagramming causality can help us structure better analyses — a giant step forward in bias science. But, at the same time, there’s scant accompanying recognition of the complexity of the larger systems in which their case studies — gender bias in science and racial bias in police shootings — occur.
Strategic behavior and information effects are relevant but not modeled. For instance, women might signal greater availability to dedicated childrearing through selecting into careers with lower opportunity costs for lost labor-years. Police might signal greater willingness to use force in black neighborhoods due to higher gun violence rates therein, to deter the other kind of police shootings.
So these are important and top-rate projects that do exactly what they say they do. But they have a limited scope because of the limits of DAGs.
We need to extend these sorts of projects to also model equilibrium effects. This is important first if we want to offer net effect analyses, the main interest of policymakers and the public. And second if we want to offer hope that we can change things for the better. Because maybe by incorporating feedbacks into causal models, we can discover where small disruptions can shift equilibria and alter collective behavior in unpredictable ways.
Private information constraints, which involve feedback
One reason DAGs fail at estimating bias in the real world is that they assume we can observe and represent everything that matters. But often, the most powerful causal mechanisms in human systems come from what we can’t observe: beliefs and reputational dynamics that embed information as private.
Private information in this context includes not only unobserved variables, but belief-driven and reputation-mediated behavior. People act on what they expect others believe, and strategically tailor their actions to influence those beliefs. For instance, men with stellar reputations may defect from parental duties because they believe they won’t face sociopolitical penalties. Similarly, police officers may selectively enforce laws (or even break them) based on anticipated monitoring or reputational risk, or lack thereof.
As social and political animals, we constantly respond to feedback loops involving private information. Belief shapes behavior, which shapes belief again. People who perceive or project no sociopolitical consequences to themselves from bad private behavior (a failure of deterrence) might opt to engage in it — in contrast with people who do. We need to model that cycle and what triggers/silences the loop. This exceeds DAGs’ representational scope.
This kind of recursive, belief-mediated, reputation-sensitive structure is impossible to represent in DAGs. The deterrent effect of a policy (say, a vaccine mandate or criminal penalty) isn’t a fixed causal input. It evolves based on observed behavior and social learning. A causes B, but B also feeds back to A via belief updates, reputation formation, or anticipation of monitoring. Strategic actors adapt their behavior in response to how they expect others to interpret it.
The same logic applies in criminal deterrence, surveillance more broadly, vaccines, and hiring decisions: if you think the system works, you’re more likely to conform to group norms. Feedback kicks in. Trust breeds trust. Cooperative equilibria prevail. Private information doesn’t make defection seem rational. Or the inverse.
This isn’t just about unobserved variables. It’s about structural asymmetries in who knows what, when, why, and how that shapes behavior. For example, people select into data provision (or don’t), manipulate appearances for strategic reasons, or make decisions based on beliefs about others’ likely beliefs. These recursive, private-information-driven dynamics often resist representation in DAGs.
Perverse incentives — a private information problem?
Previously, I drew perverse incentives under Strategic Behavior in my ever-evolving causal diagrams for mass screenings for low-prevalence problems, along with ingroup/outgroup dynamics and (as a consequence) waste, fraud, and abuse.
Now that seems wrong. Let’s say, in the case of racial profiling in traffic stops, that police are incentivized to stop a certain number of drivers, and they’re expected to fill their quota in a racially balanced way so it doesn’t look racist. But the way people implement “balanced,” like the way we implement “random,” could be systematically flawed.
This could introduce a perverse incentive to over-police neighborhoods with high proportions of minority residents because they offer more plausible deniability for race-blind enforcement. If you’re stopping mostly black drivers in a mostly black neighborhood, then it’s easier to say the stops weren’t racially motivated. But this creates a feedback loop that’s invisible in administrative data and hard to capture in causal graphs: a “rational” strategic actor responding to the monitoring system itself — and reinforcing the very disparities that oversight was meant to mitigate.
DAGs don’t do strategic behavior shaped by anticipation of how one’s actions will be interpreted by others. This includes perverse incentives in this respect as another private information problem. If we want to trace the loop between incentives, private interpretation, and strategic manipulation of appearances, we need a different tool for that.
Maybe a hybrid model that can represent how reputation, belief updating, and enforcement expectations create causal cycles in complex systems. One way to represent perverse incentives might be to model them as outcome-driven modifiers — variables that alter upstream behavior based on anticipated downstream interpretation or penalty. This is again about feedback, this time institutional-level feedback acting back on what we would otherwise want to model as a variable acting on the outcome variable in the DAG.
Moderating effects
Don’t go in causal diagrams, though I keep drawing them in orange in the DCG mate of my DAGs as a note to self.
Moderation means the effect of X on Y depends on the level of Z. That is, the strength or direction of a causal relationship may often depend on the level of another variable (exerting a moderating effect).
Moderation is everywhere. For example, the benefit of tutoring (X) on grades (Y) might be larger for highly motivated students (Z). In other words, tutoring might help students do better in school, but only if they’re motivated. The “motivation” variable moderates the tutoring effect.
Similarly, a police officer’s behavior might depend not just on a suspect’s race or demeanor, but on their combination in a specific neighborhood, under specific incentive structures.
Moderating effects often show up as interactions in statistical models. But they have no analogous visual representation in DAGs, which require you to choose between drawing moderation as mediation (which it’s not), or leaving it invisible. In practice, many researchers incorrectly depict moderation as mediation, which may mislead, even when intentioned as a reminder.
DAGs are agnostic to functional form. Interactions or nonlinear effects can exist; the straight arrows don’t mean linearity. But we need to see those other sorts of effects explicitly modeled (e.g., in the statistical or SEM layer), as the DAG doesn’t alert the reader to their presence. So moderation risks being forgotten unless drawn, even though drawing it as mediation is also wrong.
So DAGs don’t capture how causal arrows get bent by context. DCGs or modeling interaction terms can sometimes help. In this way, DAGs risk supporting a flattened, decontextualized view of causality. A straight rail, when real systems have variables often looping back into selection and/or other variables.
But this is a critique of a common misuse, not of DAGs per se. One might think of it as a form of reification, a common cognitive distortion. Sander Greenland defines “statistical reification” as “treating hypothetical data distributions and statistical models as if they reflect known physical laws rather than speculative assumptions for thought experiments.” We might extend that to beware “causal reification” as “treating graphical causal model representations as if they reflect known and possibly linear causal relationships rather than speculative assumptions for thought experiments.”
Beyond moderation, DAGs can’t answer the hardest question in causal modeling: Where do we cut the graph?
Resolving indeterminacy
Math can’t tell you where to cut the causal graph.
Do we live in an agentive or deterministic world? Do security programs net advance security when they may also undermine liberty?
We don’t know, and can’t know, because we have to cut the causal graph somewhere. As usual, science can’t tell us how to make the value-laden analytical choices that make up its practical implementation. This contributes to problems of indeterminacy, because the solution is formally nonidentified. We can’t answer the question with a causal model, because the choice of such models is interpretive.
(Indeterminacy refers to a deep philosophical or epistemic ambiguity, whereas identifiability is about whether we can technically know something as a feature of the data. In these examples, the nonidentified nature of the sought-after solutions leads to indeterminacy.)
Conclusion
Simplifying is often a good strategy for getting stuff done. From Herbert Simon’s satisficing to Jack Good’s contemporaneous type 2 rationality, some of the foundational thinkers of contemporary methods have been in favor. If modern statistics has a motto, it’s probably “All models are wrong, but some are useful.”
So maybe I should just relax and learn to love the DAG (again).
But maybe there are better tools for modeling complex systems. And maybe, eventually, we’ll know more about how to use them across the sciences. And then, sketching causal diagrams might become something scientists do as a first and last step to check that our causal logic is sound before coding data, doing calculations and running analyses, and interpreting results. But not something we use to implement those analyses using do-calculus.
That seems to be one way to interpret this Taxonomy of Models from Bernhard Schölkopf’s “Causality for Machine Learning,” arraying models from most to least complete (top to bottom), where the gold standard to him as a trained physicist is a set of differential equations, but what we usually see is a statistical model alone. Causal diagrams get us further in predicting changes from interventions, which is usually what we want to know. Structural causal models further empower us to answer counter-factual questions. Mechanistic/physical models let us obtain physical insight. But we still have to go back to stats to learn from data.
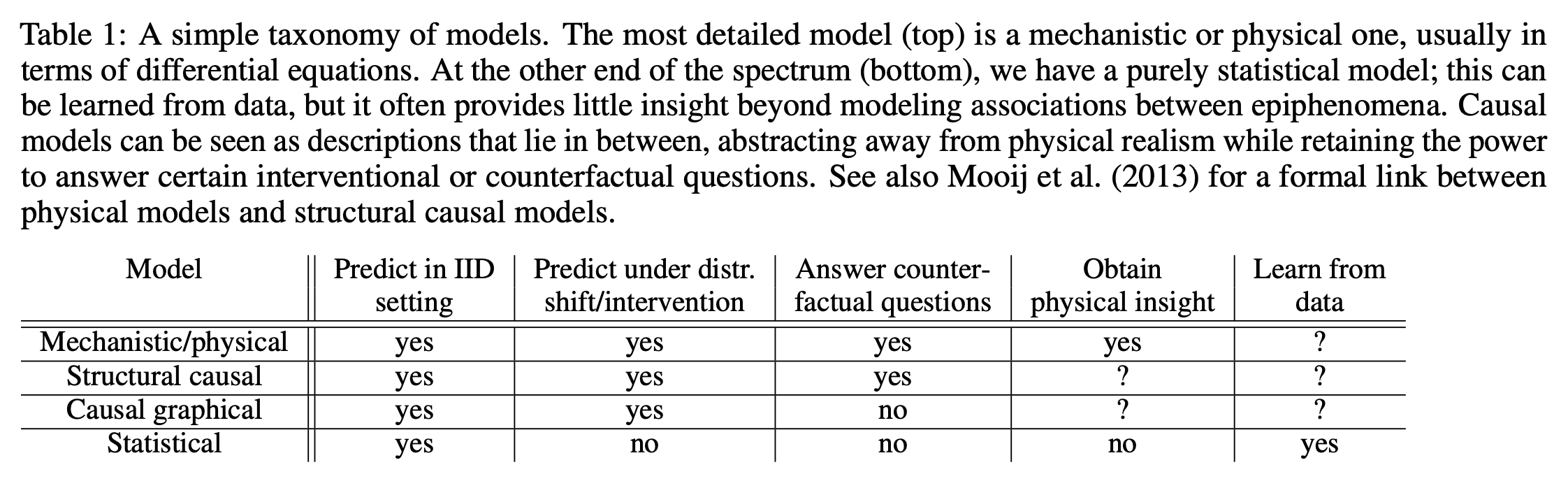
Seen in this view, DAGs remain invaluable for clarifying assumptions and structuring analyses logically, especially with respect to linear time. But when it comes to dynamic, strategic, or epistemically asymmetric systems, they don’t work. Do not adjust your sets. DAGs don’t do much of what we would like to do.
In other words, DAGs may be like the rail my son walked along: A useful, elegant constraint that helps us move in ways we’re not yet strong enough to move by ourselves. But they can’t take us everywhere. We need other tools, and to develop other skills, for that.
We need causal modeling tools that let us walk the room. DCGs look like a step in that direction because they let us model cycles, but they’re harder to identify from data and raise new challenges. Still, they open up space for feedback modeling that DAGs just don’t do.
If we want to understand and change complex systems, then we need to also use causal modeling tools that are less wrong and so more useful.