
Bear Is Back (Again)
Celebrating a reunion and focusing on what matters in science as in life


Like any good European, Bear took a summer vacation for a whole month. He was camping, as it turns out, in the box of outgrown baby clothes filling up slowly behind the sofa. His boy kept lamenting his absence all the while, alternately wishing for something scruffy to snuggle, demanding that we turn the apartment upside-down again, chastising me for having taken down the posters last time Bear reappeared, and announcing that he didn’t miss Papa Bear, at all — to the contrary, Papa Bear had been quite rude to him. (I know the feeling.)
There are probably things that matter more than seeing the boy with his bear, or seeing my kids snuggling with their doting Stateside grandparents. But I can’t think of anything more important to me than giving my children a good life with those things. The boy needs his bear, and a single mom and her two young children need their family.
This comes as something of a surprise to me, having thought the social safety net and walkability of Europe to be attributes of significant worth. But it’s always the people who make the structure, the lower-level lived experiences and relationships that color security, health, and whatever else we may value enough to move to it, vote for it, pay for it, boycott it, or otherwise use our power to shape the world that shapes us.
So I make a brief mid-summer return to fleshing out what matters in terms of endpoint definition. This is a post about focusing on what matters in health case studies of mass screenings for low-prevalence problems, as I wonder if — in addition to being in a template for a funding agency in what is perhaps the wrong country — my research proposal isn’t also currently written around the wrong cases, given that security data are generally impossible to get, but medical data are relatively accessible. (Yes, the proverb about looking for the lost keys under the lamppost “because that’s where the light is” comes to mind.)
Indeterminacy
Recall there is an under-recognized indeterminacy problem in the free will versus determinism and stochastic versus deterministic models of the universe debates: We like to dichotomize and feel like we know which world we live in, but that is silly and we don’t.
This indeterminacy may extend to the net effects of security programs that affect liberty in sequential-feedback continua. The logic of the extension goes like this: Liberty and security, like free will and determinism or stochastic and deterministic models of the universe, are all dichotomizations of sequential-feedback continua (in Greenland’s parlance). So the overall indeterminacy recurs, too. This could be sketched as a directed cyclic graph to account for the feedbacks, although we never see that done in policy efficacy analysis, presumably because the causal revolution hasn’t filtered down there yet from upper-echelon methods.
From a certain political philosophical perspective, this is intuitive: of course authoritarian security measures can undermine security itself in free societies. This is a typical civil libertarian argument against perceived state overreach, e.g., in the form of surveillance and other expansive police powers.
I’ve called this “cringe security,” since it undermines what it seeks to promote. I know, that’s kind-of a cute name for what is essentially the slide of liberal democracy into the abyss of totalitarianism. But I’m frankly less concerned with the right term for this criticism and more concerned with how the causal graph looks, what actually benefits society and what backfires, and how we could ever hope to properly measure this sort of phenomenon in any real-world context.
So does this sequential-feedback continuum problem in the causal graph extend to the medical issue area, where data are easier to come by than in the security realm? Or might some health case studies rather offer measurable endpoints that don’t get stuck in this sort of sequential-feedback continua? Would that then suggest that, in security case studies, such indeterminacy also depends — and so, sometimes, we can overcome it to suss out empirically what works?
Quality of life versus all-cause mortality
The obvious extension of liberty versus security to health is quality of life versus life (aka life extension or all-cause mortality). Trade-offs between quality of life (can you snuggle your Bear? or is he too sick and tired, or in the hospital?) and life extension (can you snuggle your Bear? or is he gone?) sit on a dynamic continuum just like those between liberty and security.
These trade-offs are not binary, but feedback-coupled: extending life might reduce quality of life in some ways, and improve it in others. The life extension improvement could well be probabilistic while the quality of life degradations could be certain, as in the case of chronic pain from breast surgery following mammography screening for breast cancer. So, optimizing for net all-cause mortality benefit (lives saved) may reduce quality of life for no benefit for the vast majority of positively screened patients.
This realization makes me continue to feel surprisingly uncomfortable with the way net all-cause mortality benefit is often treated as a gold standard in oncology in particular. It makes me want to see more data on even the best-studied programs, like mammography, so that we know better how interventions affect quality of life, too. Far from being a tough test, mortality does not look like a good enough measure of human impact when we think in terms of this continuum. Rather, it looks like (surprise) we don’t really understand the implications of what we’re doing in complex modern societies, and could be doing more harm than good on balance while wasting a lot of time and money in the process — finite resources that could go to more life-saving effective and less quality-of-life harming preventive research and care, instead, though no one wants to say that.
In health terms, this is where the number needed to treat (NNT) and the number needed to harm (NNH) become critical, since a program can save one life while harming dozens of people in measurable, nontrivial ways. But that lens simultaneously fails to account for all possible causal pathways of mass screenings, such as those often under-appreciated resource reallocation implications.
A Sketch of Causal Diagrams for Health Screenings
Here’s a sketch of two causal diagrams we could use to think through health outcomes without and with feedback when it comes to screenings:
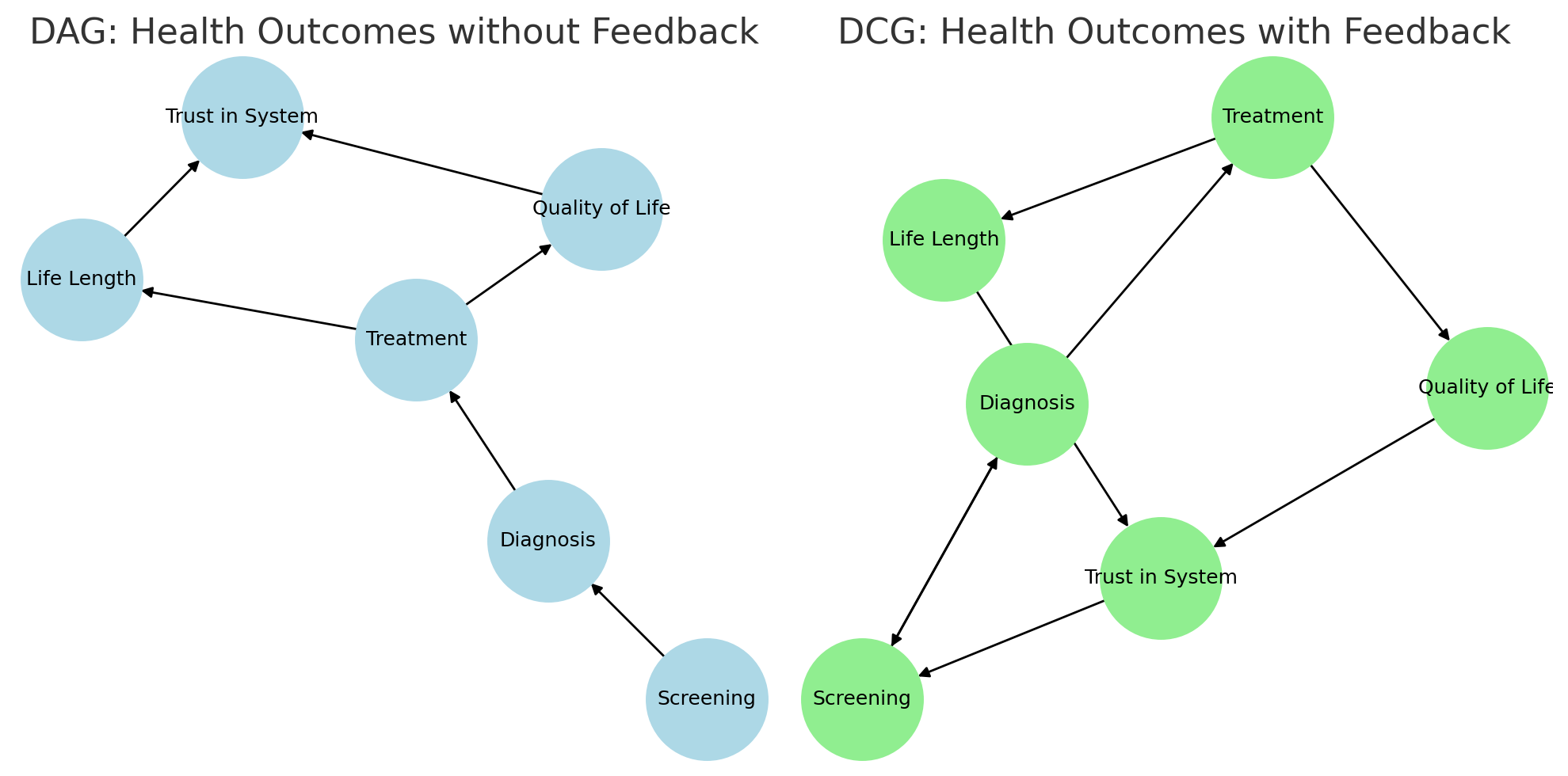
The DAG (directed acyclic graph) on the left shows the traditional model whereby screening leads to diagnosis, then treatment, which affects both life length and quality of life. These outcomes shape trust in the system, but the system doesn’t loop back.
The DCG (directed cyclic graph) on the right shows the more realistic picture where public trust feeds back into screening participation and influences diagnosis patterns. Public perceptions and systemic adaptation in turn shape health policy and individual behavior. So endpoints loop. Or, as Semisonic said, “every new beginning comes from some other beginning’s end.”
DAGs don’t handle these loops. Most health research models outcomes without them, too. That misses important real-world dynamics. Like when trust in the system shapes whether people participate in screening, or changing diagnostic thresholds reshape risk.
So we might need to reassess mass screenings for low-prevalence problems in health using cyclic graphs and nonparametric Bayesian tools that can handle these dynamics. At least in theory, these methods would allow us to model these feedback-driven systems without forcing assumptions about fixed functional forms or linear relationships, making them far better suited to capturing the dynamics that standard DAGs leave out.
In practice, however, the question remains whether those tools could use available data to reassess program impacts on what really matters. Or whether we don’t have the information we need from the experts who matter — people themselves — on the endpoints we really care about.
Part of the problem here is unsolvable. What endpoints matter hinges on values, not just data availability. Similarly, where we cut continua depends on how we make interpretive choices. These choices can be be motivated by a range of factors that really shouldn’t be setting our research agendas, like where the lamppost is.
But of course they do, because at some point, somebody has to pay for a research product, and that product would ideally be right, and to assess whether it’s right, it helps to have some data.